December 30, 2004
Firefox Downloads: 14 million and counting
Asa has posted a graph and write-up of the Firefox download numbers.

Not bad for a little Open Source project, is it?
December 28, 2004
Configuring Knoppix for Dad's Workstations
As noted earlier, I've been using Knoppix to get a pair of Linux boxes up and running for my father. Both sit on a private LAN (along with his notebook and a Deskjet color printer) via an old Netgear RP114 broadband router connected to the cable modem.
He uses a "Leave it to Beaver" theme for his machines. They are:
June
- ABit BP6 Motherboard with dual 500MHz Celeron (PII) CPUs
- 512MB PC100 RAM
- 80GB Disk
- Soundblaster Live
- 17" HP LCD Monitor
- Generic keyboard and mouse
Ward
- Pentium 4 1.8GHz CPU
- 512MB PC2700 RAM
- 2 250GB Disks in a Software RAID-1 configuration
- Integrated i810 audio
- 17" HP LCD Monitor
- Generic keyboard and mouse
The Plan
The goal was to configure both machines with a usable desktop so he could learn Linux. June will be the play system. If it gets messed up, no big deal. Ward will be the server that runs Samba and can store a bunch of the files that are also on his Thinkpad T40.
To make life easy, I turned to Knoppix 3.6 to get things started. It detected everything flawlessly, so I just had to partition each system (and configure the software RAID on Ward--that's a separate exercise) and then install Knoppix. I selected the "beginner" install, which gives you a multi-user Debian system while still retaining the fancy hardware auto-detection that Knoppix is famous for.
Once Knoppix was installed (2.6.7 kernal and all), the remaining task was to do a bit of post-installation customization and setup.
The Tweaking
I made a checklist that contained all of the things I needed to test, install, configure, or otherwise tweak. Here's the short version, partly for my records, and partly for the benefit of anyone else trying to do something similar.
Static IP addresses. I had to add a "nodhcp" parameter to the kernel at boot time. That involved editing /etc/lilo.conf and tacking that on to the end of the "append lines" for each kernel:
append="ramdisk_size=100000 init=/etc/init lang=us apm=power-off nomce nodhcp"
Then I ran /sbin/lilo to re-install the boot loader and rebooted to verify that it worked. Then I added a few lines to /etc/network/interfaces so that each machine got an address on his 129 192.168.2.0 network:
auto lo eth1
iface lo inet loopback
iface eth1 inet static
address 192.168.2.2
netmask 255.255.0.0
network 192.168.2.0
gateway 192.168.2.1
DNS. I edited /etc/resolv.conf so that it'd search the zawodny.com domain using his router as the first DNS server, and one of my coloated servers as the fallback:
search zawodny.com nameserver 192.168.2.1 nameserver 157.168.160.101
Update Packages. I next upgraded all the packages on the system. Luckily this is Debian, so it's easy with the magic of apt-get:
apt-get update apt-get -dyu dist-upgrade (marvel at the 500+ packages downloaded) apt-get dist-upgrade (answer occasional questions)
Firefox and Thunderbird. I needed to make sure he had the latest and greatest in the Mozilla world. Again, apt-get to the rescue:
apt-get install mozilla-thunderbird mozilla-firefox
That even added 'em to the KDE menu. :-)
Printer Setup. Both machines need to be able to print documents on the HP Deskjet 862C. Luckily, I could just use the printer config tool in the KDE Control Center to do that. It's a nice little front end to CUPS that made the process as easy as it would be on Windows (or easier?).
Numlock. For reasons that elude me, he wants the Numlock key enabled by default. Though the BIOS has this set already, something in Linux undoes that during the boot process. But the KDE Control Center makes that trivial again. The Keyboard config tool lets you adjust that as well as the key repeat delay, rate, etc.
sudo. We both need root access without having to type the root password. I used the visudo command to add two lines to /etc/sudoers:
jzawodn ALL=(ALL) ALL dzawodny ALL=(ALL) ALL
Clock Syncronization. The two systems didn't quite agree on time, so I manually set each using rdate and hwclock and then installed the ntp-simple package to handle keeping it in line:
rdate -s woody.wcnet.org hwclock --systohw apt-get install ntp-simple
Of course, the ntp-simple package is pre-configured to talk to a reasonable set of outside NTP servers.
SSH. For remote access, I needed to have sshd start at boot time. The cable router was already configured to forward traffic to TCP port 22 from the outside to Ward. That simple required a few symlinks from /etc/rcX.d/S20 to /etc/init.d/ssh.
Samba. The default /etc/samba/smb.conf file in Knoppix was nearly perfect for allowing home directories to be shared. I had to tweak two lines, changing a "no" to "yes" and vice-versa:
browseable = yes read only = no
Then I used smbpasswd to generate passwords for both of us:
smbpasswd dzawodny smbpasswd jzawodn
Finally, we used with XP notebook to visit \\ward.zawodny.com and \\june.zawodny.com to make sure he could map a drive to each.
Exim. I haven't done this yet, but I plan to get Exim4 running so that it can use the zawodny.com mail relay to send mail when necessary. It will use the existing TLS authentication which allows relaying for otherwise "unknown" hosts.
Ross on Family Tech Support
Ross provides his simple recommendations for the annual family tech support ritual otherwise known as the end of year holidays. In summary:
- Get 'em a Mac with OS X on it
- Get 'em broadband: it's fast and nearly always on
- Get 'em Firefox, 'cause IE is bad for your security
- Get 'em a good start page like My Yahoo or Google
- Get 'em on Web Mail like Yahoo Mail or GMail
- Get 'em on Flickr if they want to share photos
- Get 'em on Instant Messenger (I'd recommend AIM or Yahoo Messenger) and/or Skype
- Don't get 'em a blog
I mostly agree. I know that #1 is tricky and just won't fly in a lot of situations, but everything else applies nicely to a Windows box as well.
With that said, I'm off to setup my Dad's Linux machines. (Knoppix makes this pretty easy.)
See Also: How to fix Mom's computer.
December 26, 2004
Storage Costs Continue to Drop
After reading the /. story about IBM trying to build a 100TB tape drive, I found myself over on Pricewatch.com (which lamely uses frames and makes it hard to bookmark the page I want you to see). I like figuring out three things:
- Where's the current sweet spot in SATA drive prices?
250GB for $120 - How much does a Terabyte cost?
$480 buys you four 250GB disks - How much space can $1000 buy?
2TB and you'd have money left over to pay for shipping on the order
That's freakin' amazing!
I just wish laptop sized hard disks didn't lag so far behind. This 80GB disk seems downright tiny in comparison to what I could buy in a 3.5 inch form factor.
On Google Buying Flickr
Adam thinks that Flickr will be bought by Google early next year. This isn't the first "Google wants to buy Flickr" rumor I've heard, but it is the first one I've seen on a blog.
As a Flickr user and an out of the closet Flickr fan, I'm always worried when anyone talks of great little companies being bought by a Big Company. Why? Big Companies have a way of buying cool services and then making them way less cool. One of the best examples I read of that is the story of Nullsoft.
I think Google has a good track record in this department so far (namely Picasa and Blogger), but I'd just hate to see a great service like Flickr get screwed up before its time.
December 24, 2004
Giftmas 2004 Photoset on Flickr
 Given my complete disinterest in writing anything interesting for the next day or few, I've created a Giftmas 2004 photoset on Flickr. I'll probably be adding more pics over the next few days.
Given my complete disinterest in writing anything interesting for the next day or few, I've created a Giftmas 2004 photoset on Flickr. I'll probably be adding more pics over the next few days.
The shots are coming from a mix of my Philips KEY010 wearable digital cameara and my Canon PowerShot S400. I really don't bother with my Motorola V710, since it takes such nasty pictures.
Speaking of Flickr photos, my Flickr photostream is at http://flickr.com/photos/jzawodn/ and its RSS feed is here.
Where are you stashing all your holiday pics?
December 23, 2004
Ah, Midwest Winter Weather
As Josh notes, there's a lot of snow 'round these parts.

My sister just headed back outside to shovel her driveway. Last night (after it took way to long to get here from the airport) I joked that I should have bought them a snow blower for giftmas. Except that I really wasn't joking.
I think she's given up on the idea of shoveling the whole thing, instead concentrating on making two large "stripes" where the tires meet the driveway.
Here's another point of view on it:

Compare that ("ice pellets?!?!") with the weather back in California:

Heh.
On the bright side, I don't have to worry that I'm missing some great wave flying while I'm gone.
Update: Josh has posted some of the snow pictures he took.
.Slate to thank for hyperlinks?
I'm catching up on e-mail as my flight is delayed in O'Hare and came across the following tidbit about Slate Magazine in the latest Edupage mailing:
Although the magazine only recently achieved break-even status on revenue of about $6 million per year, Slate won a National Magazine Award for its editorial content, and mainstream news organizations frequently cite it. The publication is also given credit for shaping Web publishing and introducing the use of hyperlinks and Web logs.
(Emphasis mine.)
Am I reading that right? Edupage wants me to believe that Slate is responsible for introducing hyperlinks to the world?
I'm having a very, very hard time believing that.
Am I alone?
[Posted the next morning after a good sleep at my sister's house.]
December 22, 2004
Trying LaptopLane at Chicago's O'Hare Airport
During my 3.5 hour layover in Chicago, I'm trying out this LaptopLane workspace and service. It's not too bad, but is a little pricey. I should get offline soon. 65 cents/minute adds up quickly!

I know there's a Yahoo display somewhere in this airport that has (I think) free Wifi, but I'll be damned if anyone here can tell me what terminal it's in. That leads me to believe it's not in Terminal 1.
Oh, well. Off to Ohio soon. It's gonna be cold there. Really cold.
December 21, 2004
Tell us about your balls, Pete
Darren is right. One of the funniest SNL skits ever is the Christmas NPR radio spoof (57MB MPEG Video). It's amazing that the actors were able to keep straight faces.

Darren, thanks for the reminder. I had forgotten how damned funny that skit is.
December 20, 2004
Celebrex Lawsuit Demand Driving up Keyword Prices?
Over on InsideGoogle, we learn that:
Celebrex, the keyword, has soared, as personal injury attorneys scramble to buy the keyword for big bucks at Overture and AdWords, MarketWatch is reporting. The Overture cost of Celebrex soared from 95 cents on Friday to $4.02 today, following news that the FDA was considering regulatory measures for the best-selling arthritis drug.
Celebrex the arthritis drug?
Wow!
I never really thought about how FDA action against particular drugs would affect keyword ad buys. Sure, I've seen how it affects the stock prices of drug companies, but this is a bit unexpected.
It's a brave new world, with new economies that are ripe for study.
I will not write about the Giftmas gifts I bought
Because there are family members reading this little site now (and have been for a while).
However, I will say that I was pleasantly surprised at how "normal" the two retail establishments I visited this evening were. Neither felt crowded, featured those annoying bell ringers, and the checkout lines were minimal.
Maybe I should have waited a few more days... :-)
Linkblog Gone Haywire!
Err, sorry if you're a subscriber to my linkblog. I have a custom script that syncs my linkblog with my del.icio.us bookmarks, but there appears to be a bug. The result is a whole bunch of repeated postings.
I'll try to fix that later today.
Ugh.
Update: Okay, I've reworked the code for linkblog_update.pl and it seems to behave. It's no longer sensitive to re-ordering of posts in the del.icio.us dump file.
December 19, 2004
Browsers Preferred by Weblog Readers
Now that the famous Firefox advertisement has run in the New York Times, I've seen several folks publishing figures for the browser mix hitting their weblogs.
Tim Bray
Tim Bray (of Sun Microsystems) updates his chart roughly every weekend.
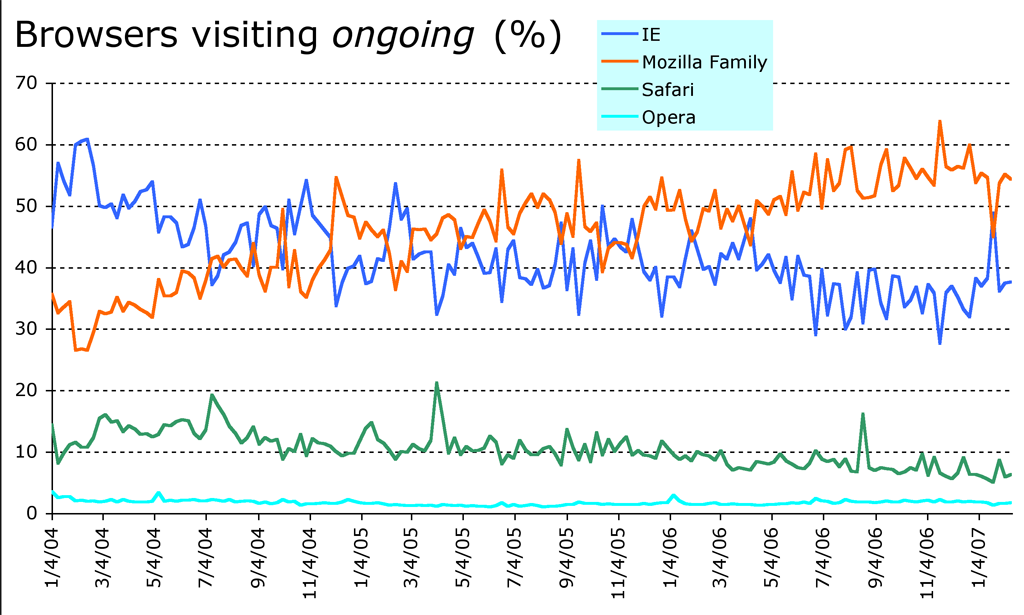
On his site, Safari struggles to hit 10%, while the Mozilla family of browsers (including Firefox) and Microsoft Internet Explorer are battling for first place.
BoingBoing
The folks at BoingBoing have posted about this recently and even make their full stats available.
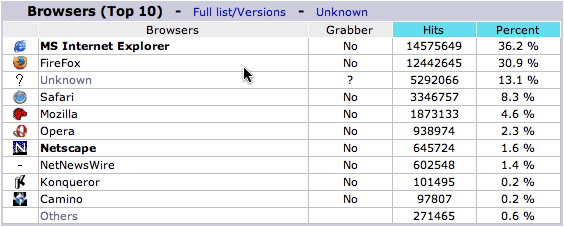
Like on Tim's site, BoingBoing has IE and Firefox nearly tied, while Safari is under 10%.
GigaOm
Earlier today Om Malik (of Business 2.0) posted his numbers and they aren't surprising either. Note that if you factor out his "unknown" hits, Firefox has a healthy share--a bit more than Internet Explorer.
(He didn't provide any cool graphic or chart I could steal.)
My blog
So I decided to play with my numbers a bit to see what they look like. The following charts are based on December 2004 traffic to date. We start with the raw data from awstats:
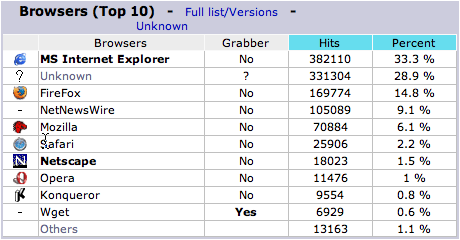
That's interesting. It seems that readers of my blog are a bit less likely to use Firefox than some of the others I've seen. I decided to remove the "unknown" ones (mainly hits from aggregators) and re-computer the percentages in excel:
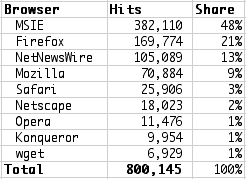
I left NetNewsWire in because I'm not sure if it represents (a) hits to my RSS feeds, (b) hits to my pages, or both. You see, NetNewsWire has an integrated tabbed browser, so those very well could be legit "browser" hits.
Anyway, if we look at this in terms of "slices of the pie" the picture is interesting:
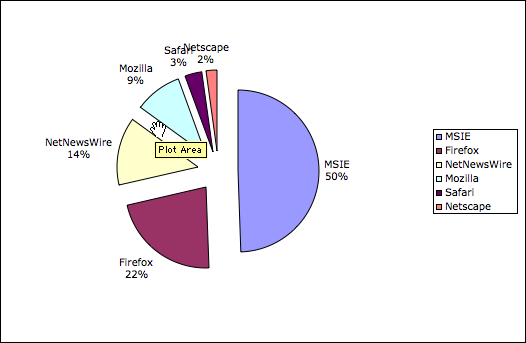
To make the pie easier to read, I tossed out the browsers with only 1% of the share. That boosted MSIE to 50% and left Firefox in second place, followed closely by NetNewsWire. That's worth looking into a bit more.
Yahoo Search blog
Then I started to wonder if the Yahoo Search blog has a similar pattern. So I pulled up the latest stats for the Yahoo Search blog. This data is from the month of December and current as of yesterday.
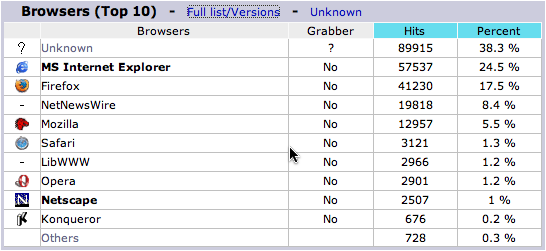
The numbers look pretty similar to what I've seen elsewhere. I am a little surprised to see LibWWW making it on the list, but whatever. And seeing the "unknown" browser bucket in first place is a little surprising too.
Conclusions
While I didn't spend a ton of time on this, it's clear that Microsoft Internet Explorer is still in the lead. But among weblog readers it certainly does not have the ~90% market share that we tend to think of it having the rest of the world.
Will this picture hold over time? That depends. Firefox may continue to grow. But as weblog readership continues to expand beyond the early adopters, we're likely to see some browsers lose ground to MSIE--at least for a while.
Comparing these numbers to those we see across all of Yahoo's properties shows some dramatic differences. But I strongly suspect I can't share specifics that data other than to say that IE use is much higher and Firefox is lower. Clearly the average Yahoo user isn't using Firefox yet. Is that a reflection of Yahoo, Firefox, or the general population?
It's probably all three. The real question is this: are the weblog numbers useful as leading indicators for the rest of the popoulation? If they are, what does that mean?
December 18, 2004
Brad Hill doesn't like recipes
Over on the Unofficial Yahoo Webog (as opposed to my weblog, which is even less Yahoo and less official), he says:
Perhaps because it is not matching Ask Jeeves asnd Microsoft by releasing a desktop search program this week, the Yahoo! blog is posting holiday recipes. Actually, it’s not even that interesting. The blog posts links to Yahoo! searches for holiday recipes. Well, you can’t have dead air in a blog.
Heh.
Well, it's good to know you're reading the blog. And thanks for the link anyway. We'll try to cook up something more to your liking. Oh, wait. We already did. :-)
Yahoo News was most cited news source by blogs in 2004. RSS a factor?
According to Intelliseek, Yahoo News was the most cited news source on blogs in 2004.
Congrats to the Yahoo News team!
I wonder if that has anything to do with the fact that Yahoo News is very blog and aggregator friendly? They've been pumping out RSS feeds and allowing you to subscribe to a news search as RSS for a while now.
I think there's a connection. I can't wait to see even more of Yahoo becoming blog and RSS aggregator friendly in the new year.
Comment Spammers Have Blogs of Their Own
Would you be surprised to know that some people who work in the search engine "industry" know who is responsible for a lot of the comment spam out there? I met some of them recently. And some of them even have blogs of their own. Seriously.
I haven't written much about this yet, but with the recent problems that have been exposed in MovableType (see: Comment Spam Load Issue, More on Comment Spamming, and Spam and the Tragedy of the Commons).
One of the comment spammers asked me: "You know why we spam blogs, don't you?" And I knew the answer. They do it because blogs are easy targets and because, just like e-mail spam, it works.
Jay Allen said:
If I chase the spammers out of my yard and onto the neighbors, it's only a matter of time until they come back. No, we all need to disincentivize these fuckers now.
He's right. And there's and 80/20 solution that ought to go a long way toward solving this problem. We know that spam works because of web page ranking algorithms based on link counting (PageRank, WebRank, whatever). But as humans, we can clearly distinguish between content posted by a blog's owner and that posted by random, anonymous, and possibly malicious users (or spambots). Search engines today seem not to, but there's a reasonable argument that it's worth putting some effort into.
If you assume the following:
- 80% of blogs are hosted by or produced on one of the more popular blogging platforms
- 80% of people don't significantly tweak the default templates available in their blogging software
- those people are the least likely to be actively fighting spam and, as a result, have more spam than the 20% of blogs where the owner is more defensive
Then a partial solution is fairly clear. I've heard and seen others discuss it over the past few months. The search engines needs to be smarter about reading and indexing content.
When folks like Tim build software that classifies pages, the software needs to be able to recognize the difference between links produced by the blog owner(s) and those contributed by readers and spambots.
Once you can identify the difference between those two types of links, you simply stop using the second type of link when calculating rank. Sure, you can still count them for the purpose of providing link counts--just donn't factor them into the ranking.
How's that for removing the incentive?
I bet you'd like to know what software the blog spammers use to run their own weblogs, wouldn't you?
Busy and Behind
 Two days of travel followed by a full day off site meeting/planning event really takes a toll. I have much catching up to do. Luckily, I'm taking the weekend off from flying to catch up on things before heading back to Ohio for a week.
Two days of travel followed by a full day off site meeting/planning event really takes a toll. I have much catching up to do. Luckily, I'm taking the weekend off from flying to catch up on things before heading back to Ohio for a week.
Lots of e-mail to catch up on, feeds to read, and so on. If you're waiting to hear form me, it might be just a bit longer.
December 15, 2004
Made it to Chicago, ate excellent Italian Food
I arrived, caught a cab to the hotel, and found Mark Matthews waiting for me. He's the main Java guy at MySQL and lives in the Chicago area. After I dropped off my stuff and sent my queued e-mail, we headed out to Gioco for dinner.
Yum.
And we got to talk tech about MySQL 4.1, 5.0 and beyond. Good stuff.
On the way back we did a quick tour of State Street and Michigan Ave.
And, hey look. I magically wrote a blog post while I was in the cab. Ah, the magic of time shifting.
If you're at SES tomorrow, come to my godawful early panel. (Remember, I'm not a morning person and I'm on West Coast time.)
December 13, 2004
Chicago Transit Advice Needed for my SES Trip
I'm heading to SES Chicago later this week to be on the Thursday morning "Web Feeds, Blogs, and Search" panel. What I'm struggling with is how to get from Chicgo O'Hare to the hotel (Hyatt Regency McCormick Place) and convention center (McCormick Place - Lakeside Center).
So far I've had very mixed messages from those who know Chicago better than I, which is--honestly, just about anyone.
Given that my flight is scheduled to arrive at 6:16pm, is it more sensible to take a cab from the airport to the hotel or am I better off with the train?
I suspect it's a case of "one is faster but it costs more" and if that's the case, can anyone ballpark how much more that is?
Also, if you're in the area and want to meet up for dinner at or after 7:30pm or so, let me know in the comments of via e-mail.
December 12, 2004
Expensive Stock Options
In doing some filing tonight I ran across some old paperwork. Sitting next to me now is a NOTICE OF STOCK OPTION GRANT from Yahoo Inc. to Jeremy Zawodny (at my old address). It grants me thousands of options to buy YHOO at a strike price of $390.25. These options expire on 12/28/2009.
Heh.
That's my initial grant from 5 years ago when I started at Yahoo. Can you say "joined just before the bubble burst?" I thought you could.
Of course, the stock has split since then, but it's still not enough to make "twice as many at half the price" that exciting.
I'm sure there are thousands of similar stories out there, many from companies that aren't even around anymore--casualties of irrational exuberance.
At least we survived.
I'll keep this piece of paper, mainly as a reminder of how crazy things really were back then.
AOL Got Some Balls
According to this AP story:
The walls surrounding America Online Inc.'s well-manicured gardens are crumbling. In a move both risky and essential, AOL is abandoning its strategy of exclusivity and will free much of its music, sports and other programming to non-subscribers in hopes of boosting ad sales.
Welcome back to the world of the relevant, AOL. It's a bold move, but it's about time you woke up and noticed the World Wide Web.
It'll be interesting to see what this means for Yahoo. More competition, surely. But better competition?
December 10, 2004
Tom Foremski on Google and Yahoo Culture
It's interesting that Tom wrote this today--the day I got to meet him in person:
Yahoo kicked the engineers aside quite some time ago. Co-founders Jerry Yang (does he still carry the title of “chief yahoo” on his business card?) and David Filo probably still do engineering type stuff, but the business is handled by people who know how to run a large media company.
Yet at Google, there are NO media professionals! They’ve done well so far, no one would disagree, but can computer engineers grow a media business? This could be Google’s Achilles’ heel.
I had lunch with Tom and about 10 others people today in Palo Alto. Sadly, I had to leave and get back to work by 2pm, but I'd have loved to stay much longer. We talked a lot about weblogs: journalist weblogs, personal weblogs, company weblogs, personal brands, and so on. Very interesting stuff that I should try to summarize some other time.
Rewind
Not too many people know this, but about two years ago I tried to leave Yahoo. I had been working in Yahoo Search (for the first time) and wasn't terribly thrilled with it and a lot of things. Obviously, I didn't leave. But I had an interesting series of meetings the day after I told a particular VP that I'd be leaving in 2 weeks.
The end result of all that was my new (at the time) role, dealing with MySQL related stuff full-time for all of Yahoo. And the rest is mostly history, some of which I've documented here on my weblog--including my move back to Yahoo Search.
However, it was during that day of meetings that I first discovered the internal confusion over what kind of company Yahoo is. I remember telling someone that I really wanted to go work for a technology company, not a media company. That led into an interesting discussion of the evidence for Yahoo being a media company vs. Yahoo being a technology company.
Identity Crisis?
Over the next couple of days, I asked a bunch of folks the question: "Is Yahoo a media company or a technology company." But it's been a long time since I've thought back on all those discussions.
Today, over a year and a half later, I see things differently.
In simple terms, you don't get to be the biggest Internet Media Company without also being one hell of a Technology Company.
So in my mind, Yahoo is both. No, the engineers are not front and center, but that doesn't mean they aren't dreaming up and building some really cool stuff. I only wish I could talk about some of the projects we've got in the works. But then I would be looking for a new job! :-(
So all I can say for the moment is "stay tuned" and keep an eye on the Yahoo Search blog, where we're going to be introducing more and more of those folks.
Maybe Tom Should Visit
Getting back to what Tom wrote (quoted above), I get the feeling he doesn't have much of a relationship with Yahoo.
A while back, Jerry Yang wrote the following in his first Yahoo Search blog posting:
While I'm not nearly as technical as I was 10 years ago (I got my hint when David Filo changed the [root] password on me so I can't touch code anymore), I firmly believe that the technology we are building today makes the future of the Web even more useful, informative, and entertaining.
Yes Tom, he's still one of our two "Chief Yahoo"s but he works on the business side of things now, not on engineering. Tom seems to think of Jerry as some sort of figurehead, but in my experience that couldn't be farther from the truth. Though he did make fun of me for wearing shorts to work in December, so he's not all work and no play. David Filo is still very much a part of day to day engineering and operations.
Tom, if you think the engineers have been kicked aside, you need to come visit Yahoo. I'd be glad to introduce you to some of the smartest engineers in this industry.
Email and Browser URL Extraction and Search via a Personal del.icio.us
A few minutes ago, I needed to send a note to Russell about Yahoo Desktop Search. Specifically, I had to find a URL for an internal site that he wanted to see. But I couldn't remember what the URL was or who sent it to me. All I knew was that it was in my e-mail inbox. Somewhere.
So I ran a quick grep (command-line search) for "http:" and got a big list of URLs and URL-like things from my inbox. I was able to further refine the search using the word "desktop" and found the URL in no time.
A moment later, a realization struck me:
I do this a lot!
In a sense, URLs are just another type of e-mail attachment. Someone can either send you the content directly or they send you a URL to the content.
What I really need is a tool that acts like a personal del.icio.us that's automatically fed from the combination of URLs embedded in e-mail messages as well as my browser history. It could keep a database of those URLs, count the frequency with which I visit them as well as how often they appear in e-mail that I send or receive. And if it provided the ability to tag and annotate the URLs, all the better.
In fact, if it was like a private "satellite" version of del.icio.us that had the ability to check with the larger public del.icio.us that'd be even better. The idea being that for public URLs which end up in my local (private) database, I could still benefit form the collective tagging and annotation efforts of those in the outside world.
I can imagine a second generation of this system that goes a step further: fetching the web content that each of the URLs points to, storing a cached copy locally, and indexing it just like a traditional web search engine might. Bonus points for integration with something like the Slogger extension for Firefox, so that it doesn't have to store duplicate data.
If I had a copy of the source code for del.icio.us handy, I could probably get the first cut of this going in a day's time. That might be a day well spent.
Hmm. Between Firefox (and Slogger) plus Thunderbird, it might even be possible to do this in a cross-platform way.
December 09, 2004
Dan Gillmor Leaving the Merc to Focus on Grassroots Journalism
Earlier today, Dan announced that he's leaving the Merc.
I hope to pull together something useful that helps enable -- and demonstrates -- the emerging grassroots journalism that I wrote about in my recent book. Something powerful is happening, it's in the early stages and I have a chance to help figure this out.
I'm not ready to discuss the specifics yet, mainly because I have many more ideas than I could possibly try to put into practice at this point -- and we're early in the process of working out the venture's actual form.
Keep in mind that this project is now in what's known as the seed stage. It's not an operating entity yet, though I expect it will be. But we're some time away from that, with many issues to resolve in the meantime.
Wow. This is a Big Deal.
I have a quick story to tell about Dan...
Back at OSCON this year I attended his presentation about grassroots journalism and his excellent book. At the end of the talk I wanted to go introduce myself and tell him how much I admired what he's been doing. But I had to go somewhere else and there was a bit of a line.
I told myself I'd try to track him down later that day. But I never found him.
Later that evening, Derek and I were at the O'Reilly book signing event (where all the authors stand behind tables and sign their books for anyone who brings one up). I saw Dan come into the room and look around a bit. I wanted to go talk with him, but someone else was at the table chatting with us. Doh!
Much to my surprise, he saw me, came over and told me that he was a fan of my blog, etc.
I was floored!
Dan Gillmor came over to tell me that he liked what I was doing?!?! That was supposed to be the other way around!
I'm going to follow Dan's new venture with great interest. He's right about things changing. Not only did he notice before most of the world, I suspect he's going to be in a great position to lead that change.
December 08, 2004
Bluetooth Wireless Mouse Recommendation Needed
Okay, I'm really digging this full-szied bluetooth keyboard for my Powerbook. So much so, that I'm tempted to buy a second one to leave at work. But having a larger keyboard keeps my hands uncomfortably far from the touch pad.
Anyone got a recommendation for a bluetooth mouse that has more than one button (sorry, Apple) and works well with a Powerbook? I'll probably use it left-handed about half the time, so I'd prefer one that is not shaped for right-handed folks.
December 06, 2004
MC Hawking's A Brief History of Rhyme
 Oh, I knew this day would come. According to Amazon.com the long awaited wide CD release of MC Hawking's excellent Brief History of Rhyme will be available on December 7th.
Oh, I knew this day would come. According to Amazon.com the long awaited wide CD release of MC Hawking's excellent Brief History of Rhyme will be available on December 7th.
By my calculations, that's about 35 minutes from now.
Kick ass!
You may remember me writing about this back in June. I was lazy then and didn't bother to order the CD on the MC Hawking web site, instead hoping it'd become available on the iTunes Music Store or maybe Amazon.com.
Can you say 1-Click Pre-Order?
All hail Amazon.com!
Anyway, if you haven't had the chance to sample this fine masterpiece of music, I highly recommend doing so. My personal favorites are track #7 (Crazy as F#@k) and track #10 (F#@k The Creationists).
The Most Hated Advertising Techniques, on Yahoo
A lot of folks are talking about Jakob Nielsen's latest posting: The Most Hated Advertising Techniques. There aren't many surprises in there. In fact, I'd go so far as to say that he's telling many of us what we already knew--it's just that he's helped to quantify that knowledge.
Before I even had a chance to connect the two dots, though, Jeff Boulter decided to see which of the hated Techniques are in use on the Yahoo network. His findings are in Yahoo's worst advertising techniques.
His conclusion, after noting that Yahoo offers a free pop-up blocker for IE (as part of the Yahoo Toolbar):
Still, it’s time for Yahoo to clean up their act. A lot of these ads are for trashy sites which can’t be paying much anyway.
Oh, how I remember the arguments about pop-up ads at Yahoo. If you're a flame-lover those were good times. If you're anyone else, those were dark times indeed.
Jason Kottke on RSS Ad Blocking
Jason is writing about RSS Ad Blocking:
Given that people who use newsreaders are still of the early adopter sort who are used to blocking ads with Firefox or fast-forwarding through commercials with their TiVos, it seems likely that blocking advertising in RSS/Atom files might soon become an issue.
He goes on to post the responses from the authors of PulpFiction, FeedDemon, and NetNewsWire. It's worth a read. And I'm sure the discussion will be interesting as always.
But we're not a portal!
This is too funny. Over at InsideGoogle, we learn that:
the 2004 Weblog Awards (vote today!) ran a test poll back in November just to make sure the site worked. The poll? Best Portal. The winner? Google, with 75.8% of the 149 votes, versus 24.2% for Yahoo. I'm sure Google would be pleased to learn it is more popular than Yahoo, but I just know there's some guy at Google yelling, "We're not a portal!"
It's fun to see how the tide turns and turns back again. Portals are the future! Search is the future! Portals are the future! Portals with search are the future!
Someday it'll all be figured out, right? :-)
XML Weather Data Available
As Kevin notes, the release of NOAA Weather data in XML is a big deal. Not only will this make it easier for the smaller guys to start offering weather related services, it means that anyone with with a few free hours and some scripting skills can build the applications that nobody else offered.
Having written the Geo::METAR perl module ages ago (I'm so behind on patches, it's not even funny), I really get why having this in XML rather than some ancient non-human friendly format is important. The METAR spec is a pain to deal with. I'm honestly surprised that the FAA still mandates that pilots learn to read METAR coded weather reports.
Like Kevin, I also wish there was a REST interface to the data too. The old METAR feeds had that much going for them.
December 05, 2004
Affiliate Links in Search Engine Results
Former Yahoo hacker turned Feedster hacker Ray suggests that search engines are missing out by not dropping in an affiliate code in their links back to sites like Amazon.com. Near the end of that post he says:
And when I do click the product link on Google's result page, they're missing out on any potential revshare. I don't think inserting an affiliate ID would be seen as doing evil or tarnish their credibility. It wouldn't even give me pause in clicking the link, and the majority of users wouldn't notice it.
Oh, now that's just funny.
Here's a reality check: If a search engine just started dropping those codes in their results, they'd be crucified. Crucified by the technical press, the SEOs, and a bunch of bloggers. Imagine the conspiracy theories!
"Are Amazon.com results really better, or are they first because the search engine makes $0.40 if I buy that DVD?"
Oh, it'd be quite the little PR crisis.
But they do notice the sponsored links, which are mostly affiliate links anyhow. So is that real reason why nobody's using affiliate links- they're afraid it will cannibalize their sales of sponsored links?
Those links are clearly labeled as "sponsored" links. If a search engine dropped in affiliate links in their untainted reuslts, they'd suddenly be lableing a lot of their links as "sponsored" or something similar, wouldn't they?
In the traditional publishing world (that is, print publishing) there's supposed to be a brick wall between the people who work to get advertisements and those who produce content. The former often report up through or work with the Publisher, while the others generally fall under the Editor in Chief.
The same thing is supposed to be true in large financial institutions. The "analysts" are separate from the underwriters--those who work to take companies through their IPOs. The SEC frowns upon any contamination.
Given the financial ecosystems created by search engines and pay per click advertising, a similar barrier has to exist between search results and "sponsored" results.
But feel free to test your theory on Feedster. :-)
Blogs in the Yahoo Directory
In Classification fun: where does your weblog belong?, John Roberts responds to my response to his earlier post (will someone build a threaded aggregator already?!) and digs deeper into blog classification:
When you search for John Roberts, you will get this blog as the only result. Hey, at least it's included. But you don't get the category placement as a navigation hint, which was one of the original innovations at Yahoo. You do for Zawodny and a few other well-known blogs. That makes sense -- focus on what people will care about. But sort of interesting that you can only see the "Most Popular" in the Weblogs category. Makes me think that there are no other blogs categorized. I don't blame Yahoo, for the same reasons cited earlier, unless you dump them all in a category called Weblogs and just leave it at that.
Well, it's a little known fact that blogs are listed in the Yahoo Directory. Heck, I even put a few of them there myself a few years back. Sssh. Don't tell the surfers that I remembered how to edit the directory! :-)
What we really need is some better integration between the directory, My Yahoo, and other aggregators. For example, in the Computer and Technology Weblogs sub-category (where I'm listed), you'd expect to see an obvious way to "Add to My Yahoo" or at least something equivalent to the orange XML button. Or an RSS (or OPML?) feed for that part of the directory.
But we have none of that. So much for integration.
The reasons why are... Well, some are complicated and some are lame. I suspect I already know most of them and can guess the rest, but that doesn't change your expectations as a user, does it?
Of course not. And there are worse examples, but I'll spare you those.
We ought to have a unified set of blog listings and categorization between Yahoo Search, the Yahoo Directory, and My Yahoo.
Are the "Most Popular" weblogs listed in the Yahoo Directory based on the same ranking system as those in the My Yahoo mini-directory? Clearly they're not--the categories aren't even the same.
My point, however, is not to beat up on the Yahoo Directory team. (I see we've renamed it "Yahoo Search Directory" now. How long ago did that happen?) The point is that we do have a slightly deeper classification of weblogs at Yahoo. And you may or may not agree with the groupings, but it's a starting point. And it's growing. Two years ago, it was a much smaller list.
Update: John responds and we learn that he, like most, didn't know blogs were in the directory either.
Blogging The Microsoft Way
I haven't said much of anything yet about MSN Spaces, but it's been amusing to watch the reaction to their lame attempt at censorship of blogs. Even Scoble is joking about it, but I'm surprised he doesn't talk about what a dumb decision that was (the lame attempt at censorship.)
By far the best coverage was Xeni's seven deadly spaces post on BoingBoing. I noticed that even Graeme Wearden picked up on it in MSN bloggers try to foul up censorship tool over at CNet.
Getting a blog with a dirty name past the MSN Spaces controls may be fun, but it also illustrates the tensions between the traditionally free and open world of blogging and the more corporate approach of a software giant like Microsoft.
Yup, Microsoft is always providing controls that people feel compelled to sneak past.
"If you can't speak freely on a blog, what's the point of having one?" BoingBoing pointed out.
Depends on the blog, I think. I can pretty much speak freely here, but not over there. Why? Because my paranoia is less that theirs. Maybe Scoble is in the same boat?
These tensions are also apparent in Microsoft's approach to blog content. Unlike rival services such as Blogger, MSN Spaces forces new users to grant Microsoft permission to "use, copy, distribute, transmit, publicly display, publicly perform, reproduce, edit, modify, translate and reformat" their blog postings.
This is the part that really surprises me. Did they think nobody would notice? Haven't they (or Scoble) ever noticed the way bloggers latch onto stuff like this and blow it out of proportion?
Well, I suspect they'll learn sooner or later.
Update: I see that Scoble responded. It's too bad there's no TrackBack on his weblog. :-(
Desktop Search Secret #1: Data Changes Slowly
After installing a "desktop search" (how I hate that term) product, Paul Kedrosky made a good observation:
All of this is a long way of saying that one thing I have discovered in making my computer more searchable is how slowly I add to my list of files. The combination of Microsoft's lousy search tool in Windows XP, and my own sloppy filing system, had me thinking that there were millions of files here, and that I was adding tens of new files by the day. There isn't, and I'm not.
Bingo.
Unlike the web, the amount of stuff on most desktops is finite and changes very slowly in comparison. The vast majority of it arrives in the form of web pages (and downloads), e-mail (and attachments), music purchases, and possibly the occasional CD-ROM or BitTorrent or file sharing network download.
And from the size point of view, the vast majority of space is consumed by music, images, and video. The density of "searchable data" associated with a 16MB movie clip is very different than that of a 16MB PowerPoint MS Office document or PDF file.
When you think about the problem in those terms, indexing performance on a multi-gigahertz PC isn't the issue it might seem to be. Instead, you probably want to index as much data and metadata as possible.
The real trick is deciphering all those file formats. When you compare Google's toy with something a bit more sophisticated like X1's product, you notice that's one of the significant differences between them. It's no wonder that GDS is free.
It's also no surprise that both products grok Outlook e-mail.
Enigmail: Easy E-Mail Encryption via Thunderbird
 The enigmatic Troutgirl points at the Enigmail project which, aside from having a great name, may make some headway in getting e-mail encryption technology in front of the masses.
The enigmatic Troutgirl points at the Enigmail project which, aside from having a great name, may make some headway in getting e-mail encryption technology in front of the masses.
Enigmail is an extension to the mail client of Mozilla / Netscape and Thunderbird which allows users to access the authentication and encryption features provided by the popular GnuPG software (see screenshots). Enigmail is open source and dually-licensed under the GNU General Public License and the Mozilla Public License.
Having tried e-mail encryption of many flavors over the years, this sounds like it might just work. Integration has always been the killer. Either the system used a standard encryption tool such as PGP or now GPG, or it used a built-in system that didn't necessarily play nicely with others.
Enigmail seems to solve both of those problems.
Excellent.
Now, if only I could find a GUI mailer that could happily coexist with mutt (and, more importantly, my client-side Maildir e-mail storage).
Shooting E-Mail Like Bullets
Andrew Lark has managed to describe something that's been bugging me for a while know: the the sad state of corporate e-mail communications. He says:
The problem is that the average employee takes little time to communicate effectively. Or, they haven't developed the skills. Or, like it has for many, email has become like an arcade game in which we win by shooting the bastards down as they flood our inbox. What is said matters less than the quickness of the finger. This eventually develops into a deep form of gaming addiction in which we have to be ready 24x7 to fire!
I don't know what it is, but as the sphere of folks I routinely exchange e-mail with has grown beyond software engineers and ops/sysadmin guys, I've been increasingly frustrated by how bad it is. Some of the stuff I bitched about over tow years ago in ru stupid certainly hasn't gotten any better. But that was just scratching at the surface.
It's been too long since I ranted about something, here's a brief list of the the things that drive me nuts. It is by no means complete.
- Top posting. Outlook has done the world a huge disservice by encouraging folks to respond in summary format at the top of a message rather than using the inline responses that were common for so many years before this e-mail stuff became mainstream. The problem gets worse as threads get longer and I'm forced to read e-mail messages from bottom to top. WTF?! More about this: here, here, and here.
- Expectations about when I'll read a message. Honestly, if it's that important, why are you using e-mail? The first letter in "IM" stands for "Instant." Try that instead. And, like seemingly everyone else in the workplace, I wear a damned cell phone. When it rings, I generally answer it. The only real exceptions are when I'm in the restroom, when the caller has blocked caller ID, or when I'm in the middle of a meeting that is highly likely to be more important than your call. The more often I'm responding to your e-mail, the less work I'm probably getting done.
- Bad subject lines. You know, I thought we'd figured this out back in 1998 when Jakob Nielsen wrote Microcontent: How to Write Headlines, Page Titles, and Subject Lines. You can argue with a lot of what he's said over the years, but this is one of the few things that very few people dispute. If you send me a message with a subject that I cannot figure out, I'm likely to read it after all the messages with reasonable subject lines.
- Screwed up punctuation. Question marks go at the end of questions. Always. If you omit question marks, when I'm skimming your message I may completely miss the fact that you're asking me something and file it away because it seemed informational only. And don't forget about your friend the apostrophe, otherwise known as the single quote.
- Sentences without subjects. Who was it that decided we can just stop putting subjects in our sentences? I clearly missed that memo but see it happening everywhere. For example, consider this tidbit: "Recommend not using the fuzzbot image on that frumple page." There are no less than three ways to interpret that: (1) You recommend that I don't use the image, in which case the sentence is missing an "I" at the beginning. (2) The team you're speaking on behalf of has decided to make that recommendation, in which case the sentence is missing a "We" at the beginning. (3) You are commanding me to make the recommendation, in which case the sentence is missing something like "I suggest that you" at the beginning. If you leave it up to me to figure out exactly what you mean, I'm always going to choose the one I most like.
- Broken threading. This is more a complaint about tools than anything, but some of the most popular mail software creates messages that are difficult to thread properly. Worse yet, they don't even offer a thread-based message view for their users. And the lame "group based on message subject" is not threading. Top posting doesn't help here when I'm trying to "manually" thread messages.
I really don't know what we can do about this. For some of it, I think we need better tools--much better. It's clear to me that not only to most people not "get" how e-mail quoting and threading work, they just don't care. Web-based mail services like Yahoo Mail, Hotmail, and GMail only serve to lower the bar further.
But some of this simply requires people to (1) care about their communication, and (2) take the time to do it well. Sadly, both of those seem to be rare.
I'm tempted to not allow comments on this post. I know it's going to mainly attract people who are looking for a good flame war. Oh, and it'll bring out a few of those who think that I'm somehow not entitled to an opinion--especially an "elitist" one.
</rant>
How you say "packet loss"?
 A couple hours ago I noticed that fetching my e-mail was getting really slow. In fact isync was just stalling. At first I thought it would be high disk utilization on my server. It wouldn't be the first time.
A couple hours ago I noticed that fetching my e-mail was getting really slow. In fact isync was just stalling. At first I thought it would be high disk utilization on my server. It wouldn't be the first time.
But then I tried to ssh to the box and noticed that was taking forever too. Hmm. I fired up mtr and captured this screen shot. I guess that pretty much speaks for itself. But it won't stop me from saying how screwed up the ORANet network seems to be.
Oh, well. If you tried coming to my website and noticed it was slower than normal, blame ORANet. Or blame me for parking that server on a network served by ORANet.
The lack of decent connectivity motived me to continue cleaning up my office. Now I've got all my flying related books, magazines, and paperwork in one place. At this rate, I'll have everything organized in another month or three.
Ugh.
December 03, 2004
Weblog topics, blogger micro-brands, and weblog classification
John Roberts notes that:
One of the oddities for me in thinking about blogs is that there is rarely a sense of someone staying On topic in the sense of traditional publications. If you read the Wall Street Journal, you know what you're going to get, and where you're going to get it, often to the column on the page. If you read CNET News.com, ditto...
With blogs, you're reading about individuals, and most of us have -- and share -- varied interests. Some folks even blog about those different interests in the same place, with or without categorization. That diversity -- all in the same blog -- is part of the appeal for me, but it sure makes it hard to categorize different voices into coherent groupings.
This that's something that a lot of people, especially those new to reading weblogs, just don't seem to get. They fail to see what's really happening. Many of us who write regularly are becoming our own micro-brands, just like magazine and newspaper columnists do. They build an audience that sometimes is loyal enough to follow them from publication to publication during their careers.
To the early adopters, among which I count myself, the names above often mean something, whether you know them as a person or not. Some of the labels stick. But the reason this still works is that the early adopters in the blogging world are still a small group, David Sifry's numbers be damned.
Well said.
I don't read Jon Udell's writing because he writes for Byte, Infoworld, or any other publication. I read his stuff because I like what he writes. He's a smart guy who writes interesting stuff. While his weblog is a lot more "professional" than mine or Tim Bray's (no offense, Tim--we both talk about non-work stuff regularly), the same reasoning applies.
Amusingly, he also uses me as an exmaple:
But how do you describe why you would read, for instance, Jeremy Zawodny's blog?
I won't attempt to answer that, but it does give me an idea for a little reader survey. I do wonder, among other things, how many of my blog readers also read my columns in Linux Magazine.
His other point, made later on, is that blog classification is difficult. When the new My Yahoo launched, I told Scott Gatz (and several others internally) how I was amused by finding myself listed in the Living & Lifestyles category of our little content directory that helps users to find content.
I'm no Martha Stewart, but Wil Wheaton and Jeff Jarvis are in there too, so whatever. I guess that's where bloggers go. Notice that in the Internet & Technology category, it's exclusively Yahoo content on the first page.
Even the surfers at Yahoo aren't sure what to do with us! :-)
December 02, 2004
Grokking Bloomba
 Earlier today... err, yesterday since it's well after midnight (again), I had lunch with Patrick Hunt and Raymie Stata. That last name may sound familiar because Raymie's company, Stata Labs, was acquired by Yahoo earlier this year. Like Oddpost, another smaller company we acquired, they built an e-mail client. Stata's client is called Bloomba and I got a brief demo of it from Patrick (also from Stata Labs) before we headed over to URL's for lunch.
Earlier today... err, yesterday since it's well after midnight (again), I had lunch with Patrick Hunt and Raymie Stata. That last name may sound familiar because Raymie's company, Stata Labs, was acquired by Yahoo earlier this year. Like Oddpost, another smaller company we acquired, they built an e-mail client. Stata's client is called Bloomba and I got a brief demo of it from Patrick (also from Stata Labs) before we headed over to URL's for lunch.
Boomba is an interesting product. Unlike Oddpost, which is a rich web-based e-mail client, Boomba is more of a traditional desktop application. Bloomba is designed to manage a large volume of both e-mail and RSS feeds. It has both folders and tagging for messages, which I'm now convinced is mandatory for anyone that deals with a lot of e-mail, and it provides a mechanism for "saved searches" or views if you're thinking of it from a database mindset.
The more we talked about Bloomba after the quick demo, the more I realized that it really is a good combination of ideas. Like Oddpost or NewsGator, it assumes that you want to use a single program and interface to handle incoming e-mail as well as news (RSS/Atom) feeds. The "saved search" feature is quite similar to the Smart Feeds that NetNewsWire offers for news feeds. (I happen to use have several smart feeds in my NNW setup.)
 Bloomba also has something that I haven't seen in many other places: automatic aging. The idea is that items should no longer appear as "new" after they reach a certain age, regardless of whether or not you've read them. For many news feeds and e-mail lists, this makes a ton of sense. There's a whole collection of feeds I subscribe to mainly for the purpose of being able to include them in the universe of feeds that my smart groups cover. It's rare that I actually read those feeds directly.
Bloomba also has something that I haven't seen in many other places: automatic aging. The idea is that items should no longer appear as "new" after they reach a certain age, regardless of whether or not you've read them. For many news feeds and e-mail lists, this makes a ton of sense. There's a whole collection of feeds I subscribe to mainly for the purpose of being able to include them in the universe of feeds that my smart groups cover. It's rare that I actually read those feeds directly.
The same was true of some mailing lists that I've since unsubscribed from. The SpamAssassin list, Linux Kernel, and several others were very high volume but only produced truly interesting information for me once or twice a month.
The result of the demo, subsequent discussion, and thinking is that I want a Mac version of Bloomba. Or maybe I just want NetNewsWire to grow until it acquires the ability to send and receive e-mail, as all software eventually does. :-)