April 29, 2004
New PowerBook Ordered
I always said that when I finished the book that I'd get myself a new notebook. Early on, I expected that'd mean a ThinkPad T40 or something similar but that all changed a little while ago.
Thanks to an ADC hardware discount, I've finally ordered the new hardware. The order I placed via Apple Store is:
- PowerBook 1.5GHz (15.2 inch)
- 128MB Graphics Memory
- 80GB Ultra ATA Drive (4200 rpm)
- SuperDrive (DVD-R/CD-RW)
- Backlit Keyboard
- 512MB DDR333 SDRAMM (1 DIMM)
- AirPort Extreme Card
- ApleCare Protection Plan (3 years)
- 40GB iPod
- iSight
- World Travel Adapter Kit
- Spare Battery
And I also ordered a few accessories from Amazon.com:
And I ordered an additional 512MB DIMM from Crucial.com. I really wanted to get more than 1GB in the box, but doing so is far too expensive right now. Maybe in a year.
After I get everything setup with the new hardware, I can go about the business of selling the old machine (TiBook 550MHz) and selling Dan my old 20GB iPod, assuming he still wants it.
There's no turning back now. I've switched. Or at lest I've paid for the switch.
In a few weeks, I'll probably be shopping for a new cellphone, eyeing those with BlueTooth so I can be like the cool kids.
Off to Cleveland
Very early Friday morning, I'll be headed to Cleveland for Brandt's wedding. Other blogger friends attending are: Dan, Kasia, and Morgan.
A few folks have asked if there'd be time to meet up in Cleveland, but I doubt it. This is going to be surgical strike trip. Arrive Friday afternoon, wedding on Saturday, head home on Sunday. There's not much time left for other stuff.
On the weather font, it looks like rain there. Ugh. I'm gonna miss the sun and low 80s we're having here now.
April 28, 2004
I'm running out of Gmail invites
You'd think I was giving out free money or something.
They're not pre-IPO shares, just gmail invites.
It's funny. Almost nobody asked me for an account until I mentioned it on a mailing list earlier today. Now I've probably sent out 20 invites in 10 minutes.
A few smart cookies assumed I had some invites stashed away when I first talked of spamming my gmail account (thanks for all the "spam", btw). I purposely didn't mention invites because I wanted to see how long they'd last if I didn't.
The answer: way, way longer than expected.
Now I guess I need to be selective or something. If I was greedy, I'd just run a dutch auction on eBay or something. But I won't. Direct PayPal is so much easier!
Just kidding.
Unless I'm not.
I figure that this post will pretty much clear out what remains of my invite quota.
Update: Yeah, that was pretty effective.
Signs Your Company May Be Too Big
This is by no means complete. But I figured I ought to write down those that have occurred to me recently.
- it takes at least one month to get new test hardware
- there's a constant parking shortage
- everything has a form that must be filled out, such as "I want to ship a package to someone" when you're in the shipping room
- the fact that you have a loading dock upon which you can fill out that form and a shipping/receiving staff to process it
- everyone seems to have a different job title and the new ones seem to sound way more important than they actually are
- taking a job interviewee to lunch at the cafeteria and not being able to find three empty spaces where you can sit with him and one other person
- you have a full-time person dedicated to helping employees figure out ways to optimize their commute
I'm sure others will add things that I haven't experienced or thought of yet. If you do decide to add your own, please omit the obvious Office Space references. I think we all know them by now. And I'd hate to start that virus all over again.
Well, hmm. I think "hate" is a rather strong word.
Official Weblog of the Internet
I'd like to formally announce my weblog as the official Weblog of the Internet. I figure that if Pentax can announce the Official Digital Camera of the Internet with apparently no IETF or ISOC input, I can do the same for my weblog.
Or maybe someone needs to ask Pentax just what "official" means in this case?
Update: Okay, I was a few months too late. But as JR suggests in the comments below, I'm going to claim the title of "Official Web Site of The Internet" instead. I should get some t-shirts made up.
April 27, 2004
TMDA Users Can Blow Me
This is freakin' stupid.
First of all, I never respond to anti-spam e-mail "challenges" whether they are from TMDA, SpamArrest, or anyone else. Ever. On my personal e-mail account, I have a procmail rule that ensures I almost never see them (unless they're heavily customized and my rule misses, of course).
A reader (of the book) just e-mailed me (at my work address for some reason) to ask a question. I spent the time to answer his question only to be rewarded with a message (via his TMDA install) that he's not going to read my message unless I jump through another fucking hoop.
Screw that!
You know why?
HE CONTACTED ME FIRST!
If these systems are so brain-dead as to not bother adding my address to the whitelist when the user sends me e-mail, I have serious trouble understanding why anyone is using them.
Is it just me? Is this too hard to figure out?
Anyway, there's another 5 minutes I'll never get back. It's too bad there's no mail header to warn me that "this message is from a TDMA user", because then I'd be able to procmail 'em right to /dev/null where they belong.
Ugh.
This bullshit is not going to "solve" the spam problem, people. If that's your solution, please let me opt out. Forever.
</rant>
April 26, 2004
Northern California Vacation Ideas Needed
Okay, here's the deal. My parental units will be visiting the San Francisco Bay Area (well, me, and I happen to live in the Bay Area) in a little while--early June to be exact.
This will be their third visit. In the past we've been to Sequoia National Park, Yosemite National Park (more), The Hearst Castle, The Monterey Bay Aquarium, Big Sur, Pebble Beach, a brief visit to Napa, and a lot of the local stuff as well (San Francisco, Tech Museum, Winchester Mystery House, Chabot Space and Science Center, The Lick Observatory atop Mt. Hamilton, etc).
This time around, we'd like to hit some stuff up North and East and are looking for ideas. Our current thinking is that we'd like to spend a few days up in the Lake Tahoe area (possibly Reno?) and maybe hit something interesting on the way there: Sacramento or maybe some of the old gold towns? Ideas? Recommendations? Stuff to avoid?
Oh, I'll just have to give a glider ride or two up at Truckee too. :-)
As a separate excursion, we'll probably also visit the Napa/Sonoma area for a couple days as well. The only thing we have planned so far is a lunch ride on the Napa Wine Train. From there we'll probably head farther north up the Mendocino Coast. Again, any ideas, recommendations, or stuff to avoid in the area?
At this point I'm trying to cast a net and see what kind of ideas are out there. My parents are not the type to get out and hike five miles, but they do like scenic areas. If possible, we'd like to avoid the most touristy and crowded areas unless they're really worth it.
Let's see, what other parameters can I provide? Hmm. Stuff like one-day boat rides on a river somewhere would be right up their alley. We're not terribly big on [most] museums.
Even recommendations on scenic routes, places to stay/east, etc. are all welcome.
We'll likely also try to hit a few local things (such as a trip to Hollister for a glider ride or two), so any suggestions locally would be cool too. Is there anything worth seeing or doing in Gilroy? It's on the to and from Hollister.
I've been thinking that the Computer History Museum might be fun, but Mom probably wouldn't like it very much.
Anyway, I'll stop rambling now and hope someone out there has a good idea or two. Thanks in advance for any that turn up!
April 24, 2004
Decent Local Soaring
I planned to fly in the informal Hollister League contest today. Since I flew the novice task two weekends ago with Jonathon, I figured it was time to do it on my own. At the morning pilot's meeting, Ramy called a task of Panoche (lookout towers) to Black Mountain and then back north to the Lick Observatory atop Mt. Hamilton.
Ramy had suggested that a local start (tow to Three Sisters, find lift, work down to Panoche) might work. I was intrigued by the idea and decided to give that a go. It's a good thing I did, because while I was taping the wings on my glider, I learned that everyone was towing to Three Sisters due to a shortage of tow planes. I launched 3rd to last (just after 2pm), ahead of Drew and a student in the Duo Discus and Steve in CA.
I felt several really good thermals on tow and got little cocky. I released at 3,800 feet about a mile and half from Three Sisters. As I flew toward Thee Sisters, I encountered nothing but sink! In fact, I arrived over Three Sisters at about 3,300 feet (only 300 feet above the altitude at which I'd normally head home) and began looking for lift. After a minute I was rewarded with a decent thermal that allowed me to climb to roughly 6,000 feet. I didn't know it then, but that was to be one of my best thermals of the day.
As time went on, I started to hear problems on the radio. The guys who were going south were struggling. Some were struggling a lot. Russell came really close to landing at Hernandez. A few guys turned back to Hollister at EL2. Ramy eventually shortened the southern task to Center Peak. I heard about four guys make it all the way to Center.
All that made me decide to stay local. I searched around the east hills a bit and could only find that one really good thermal and another one a couple miles away. Everything else was 4 knots down. The normal spots (microwave towers, tin roof) weren't working at all.
Steve eventually reported lift the Pacheco Pass, so I headed that way. I stopped along the way for one thermal but it was a weak one and not really worth the effort. As I got to the pass, I noticed that there was lift in a few spots. I spent the next hour or so playing around there. I'd get high, fly toward the peak and lose all my altitude and then return to the thermal to try again.
After about 3 hours, I decided to burn of my altitude and return to the airport. My landing was much better this time. Even though the plans didn't work out for the contest, I enjoyed my day of soaring.
April 23, 2004
Mail.app, mutt, mail volume, and e-mail addiction
Since I've been using the Powerbook (which I still need to replace with a newer one now that the "speed bump" is official), I've drastically changed my e-mail habits (personal mail, not work mail). In doing so, I wonder if I'm unusual in this respect.
Previously, I was using mutt for e-mail on my IBM Thinkpad running Linux. If you've not tried it, mutt is really the king of all console-based mail programs. It excels at making it very easy to read (maybe "process" or "manage" is more accurate?) massive volumes of mail every day. Or hour.
And that's the problem. Because mutt makes it easy to handle lots of mail, I found myself on a ton of mailing lists. Remember, easy doesn't mean "requires zero time", so I also found myself spending a lot of time every day processing e-mail--most of which I really didn't read. I just skimmed subjects.
After replacing mutt with Mail.app on Jaguar (no, I'm not running Panther yet--the new machine obviously will have it), I found the need to reduce my incoming mail volume. A lot.
This bothered me at first, because it made me feel like I was using an inferior tool. But having gone through the exercise of cleaning out old folders, fixing a few procmail rules, and unsubscribing from an assload of mailing lists, I'm a lot happier. I spend way less time reading e-mail and really don't miss skimming all that stuff I was never going to read anyway.
Sure, there was an initial period during which it was surprisingly unnerving to check my mailbox every few minutes and not find something new to read, but that didn't last more than a week.
It's kind of like watching TV. Since I stopped, I haven't missed it a bit. I don't even know where the remote control is anymore. More productive and interesting things fill those hours now. And the $12/month (or whatever if costs) from the Tivo subscription can be put to some other use.
Probably Skittles.
mod_tourettes
mod_tourettes, or more correctly "mod_tourette's", is an amusing idea that I have no time to implement. But I figure there might be someone out there who's done something like this (or wants to).
It's an Apache module that will randomly insert profane words and phrases into HTML pages it serves. The idea came up when Derek and I were talking last week during the MySQL Conference. I really don't remember how. Perhaps he does.
See also: lots of sites on Tourette's Syndrome via Google.
April 22, 2004
Two MySQL Related Job Openings at Yahoo!
![]() I know I've tried this in the past, but we're still looking...
I know I've tried this in the past, but we're still looking...
Here's info about two MySQL related jobs at Yahoo! I've also included my personal take on some of the benefits of working at Yahoo below them. If you're interested in either job (or one of the many other job openings at Yahoo), please send me your resume (plain text, PDF, or OpenOffice preferred, MS Word not).
If you know someone else who might be interested, pass this along or send me their e-mail address. I'll gladly nag 'em if you think it's okay. Both jobs are on-site at Yahoo! headquarters in Sunnyvale, California. Relocation is available, I'm told.
MySQL Database Architect [new!]
Yahoo! is looking for a MySQL Database Architect to work in the Yahoo! Business Continuity Team. We are looking for someone who wants to make a difference and is up to the challenge of working on key Engineering projects that are critical to Yahoo!
Are you interested in working on multiple properties (Mail, Messenger, My, Search) within the course of a year? In this position you will use your strong technical background and excellent interpersonal skills to implement small and large-scale projects and collaborative efforts. Successful candidates will play a key role interfacing between all Engineering teams to design and implement high availability systems.
Requirements: 6+ years experience designing and delivering large, high-performance commercial databases (Oracle, DB2, Sybase, Informix) for premiere Internet-based applications; ability to collaborate with Engineering and Product teams to design extensible data models that fulfill application requirements; ability to perform hands-on query optimization, data analysis, and database tuning; 3+ years experience with MySQL; excellent written and verbal communication skills and data warehouse experience.
BS in Computer Science or related discipline is required
Experience in system architecture and design, especially within a multi-located datacenter. Perl, mod_perl, OOP, Java, C++ are all requirements.
Experience with all aspects of web development: including strategy, design, functionality and implementation.
Yahoo! Mail Operations Engineer [repost]
The Yahoo Mail Operations team is looking for a highly dedicated, motivated, and experienced software operations and tools development engineer. The Mail operations team is responsible for overall performance, availability, reliability and scalability of several large-scale systems involving thousands of servers and hundred of terabytes of data.
To be successful, you must have at least 4 to 5 years of experience with the following skills: UNIX (shell scripting, gmake, awk, sed and/or other unix system administration tools), perl, site monitoring such as NetSaint/Nagios, site operations/networking (VIPs, ssh, cron), C++ (some exposure), production database installation and/or configuration (MySQL or Oracle). Prior experience with operations in 24x7 production environment is highly desired. You also need to have good communication skills, schedule flexibility in working with offshore engineers. BSCS or equivalent is required.
Working at Yahoo!
Yahoo is a large, stable, and profitable Internet media company. Everyone has heard of Yahoo. But why would you (the smart engineer) want to come work here?
Lots of reasons. Here are several benefits, off the top of my head:
- good salary
- great technology (we love open source)
- lots of smart people (I guarantee you'll learn a lot)
- on-site gym
- employee stock purchase program
- products that millions of people use
- stock options
- flexible hours
- heated engineering debates on internal mailing lists (fun and informative)
- bonuses
- great medical/dental/vision plans
- 401k plan
- telecommuting
- climate that's hard to beat
- vacation time
- paid relocation
- impact--being a big company doesn't have to mean you're just a number
- live within driving distance of san francisco, napa, tahoe, yosemite, and more
- the chance to go head-to-head with microsoft, google, aol, and countless others!
I'm sure there's more. Maybe some of the other Yahoos reading this will chime in with their favorite reasons for working at Yahoo.
Disclaimers
I didn't write either job description. Details subject the change.
If you're invited on-site for an interview, there's a good chance I'll be interviewing you. So don't BS about your MySQL experience--I'll know. And if you accept a position and list me as having referred you, I get a reward. But that's really not why I'm trying to find people. We need good people for these jobs, and getting them will make my life easier.
Tivo Sucks Like Audible.com
A while back I ranted about Audible.com making account cancellation difficult. Well, our friends over at Tivo are no better.
After browsing around their "customer service" site it became apparent that they were more than willing to take more of my money on-line, but heaven forbid they let me cancel service.
Instead I found a page that explains that I must call Tivo to arrange for that. Nowhere on the page do they provide justification for this inconvenience, of course.
Sill me. I thought the web was going to improve customer service, not make it more difficult to perform an otherwise simple task.
And don't even get me started on the IVR system you have to get thru before speaking to a human.
Amusingly, when I cancelled and told 'em I sold my Tivo, they asked if I "sold it locally or on eBay." Yeah, as if it's any of their damned business.
April 21, 2004
Understanding the MySQL Release Cycle
In his MySQL Conference Roundup post, Russell confessed his confusion about how MySQL versions are numbered and developed:
I was actually disappointed to hear that 4.1 won't be going beta until next month and won't be in production until Q4!!! I was told it was going to be production *a lot* sooner (as in this week). Urgh. As I'm using the spatial indexing stuff, and it'd be nice if it was more solid. And what about 5.0? I thought 4.1 was going to become 5.0 when launched? I'm confused.
Heh. It is confusing, especially since different projects do it differently (Linux kernel, Apache, etc). The good news is that MySQL is fairly easy to understand.
There are always at least three versions (or categories of versions) to know about. Let's give them names and rough descriptions that match the way I think about it.
- legacy: these versions are no longer actively developed. If you find a bug, you're usually told to upgrade to stable. Major security flaws, however, generally seem to be fixed. Today this is the 3.23.xx series.
- stable: the stable series is safe for use in production. Bugs are actively fixed and new versions appear a few times per year. Today this is the 4.0.xx series.
- development: this is where all the new stuff happens. The code may or may not be safe for production use at any given time and may or may not exist as alpha or beta releases as they reach major milestones and need testing. Today this is both 4.1.xx and 5.0.xx
That last bit is where the confusion comes from. The 4.1.xx series is likely to go beta in a month or two (I'd guess). It's where you're going to find spatial (2-D) indexing, subqueries, multiple character set support, prepared statements, and lots of other goodies. The 5.0.xx series is going to take longer--just as you'd expect. It's where the work for stored procedures is going on.
So 4.1 will not become 5.0 when launched, but 5.0 will certainly inherit all of 4.1's features.
It's also worth checking the relevant section of the MySQL manual to get their take on all this.
Oh, he also heavily pimps High Performance MySQL in that post too. Thanks, Russ!
When working from home...
It's important not to fall asleep, because well... then you're not actually working, are you?
The perils of working on a laptop in a lazy boy chair, I guess.
But I think it's really my cat's fault. He saw me lean back and stretch. Then he jumped up on my chest and I figured "I'll let him stay, but just for a minute."
Whoops.
It was a good nap, though. Brief, but good.
I think I'll move back to the desk or table for a while.
In other news, the dentist visit was fun as always, and the Comcast guy got my cable modem working. He didn't even flinch when I handed him a Mac notebook with OS X to use. He'd never seen Firefox before, but that hardly mattered.
I now have redundant ISPs at home again! God, I'm a geek.
Now where's that config file I was tweaking...?
April 20, 2004
Weblogs as Weapons (sharper than knives)
Pardon the INXS reference, but it seems appropriate.
We've all heard that weblogs are conversations, and we often assume that they are generally productive conversations. Even when someone (like me) posts a bitchy or uninformed entry, there's often some little bit of good to come out of it. That's generally a testament to my readers. Some have an uncanny ability to see what I'm getting at even when I can't quite seem to make my real point.
But it's not always like that.
A couple days ago, I noticed Dave Winer's scripting.com show up in my hourly referer log summaries. He had linked to my Blinded by Gmail's Gigabyte post (that now has over 50 comments--wow!) in which I react to Tim O'Reilly post on Gmail and the "Internet OS" meme (mostly focusing on that meme rather than his entire post).
Now Tim's a really smart guy and did a good job of blasting folks for going nuts over the Gmail privacy debate. And his company publishes my book. So I clearly don't think he's evil or anything.
I agree with Tim that it's all become way too stupid. And I further agree with Rich Skrenta's post about the Google platform that got a lot of people thinking. In fact, I've been thinking about that off an on for a couple years now--about the fact that Google has a fundamentally more innovative architecture that Yahoo does. And I wonder what that means for Yahoo. (More on that some other day if I can convince myself that I won't get fired for saying what I think on the matter.)
But that's not what this post is really about. When Dave linked to me, I half-jokingly suggested to Kasia that Dave might have some sort of grudge against Tim. (Remember Foo Camp?)
Why? Because he used this quote: "Even Tim O'Reilly seems to be sucked in by Google's reality distortion field now." instead of something like "For god's sake, it's web mail with a really big quota!" which was what I expected someone might use. Either that or "Jeremy's pissing on Google again. Does Yahoo pay him to do that?!" :-)
Then a few folks said the same thing (completely out of the blue) via private e-mail to me. I wondered what his motivation for the link was, but didn't think too much about it. Maybe he just thought it was a good headline, since that's his blog style much of the time.
Then, before I had a chance to notice today, it seems that Dave linked to it again but this time directly to Tim O'Reilly's comment. In that comment, Tim notes that he does in fact own a bit of Google stock (as does my employer--but probably a bit more than Tim does), which he got as the result of an acquisition.
This was pointed out by Kevin Fox (a Google employee with an excellent weblog) in a comment on that same post.
If you're going to potshot, don't do it by manipulating blogs like Jeremy's, or seeking to slander luminaries like Tim. They're both out of your league. If you want to keep slander as your weapon of choice, bring it to me.
Now I'm starting to feel a bit used. And I'm starting to think that my joking suggestion of Tim owning Google stock wasn't such a bright idea.
What am I supposed to think of this, Dave? Is this why Mark Pilgrim blocks referers from your site? Did you also try to use his content against someone else you disklike in the past? Your terse linking style leave a lot of room for interpretation.
Spam My Gmail Account
Well, not literally. But I need to get a sufficient volume of mail into jzawodn@gmail.com that I can get a better feel for what it's going to do. You know, to see past the gigabyte and all.
Sure, I'll probably dig up some stuff from my archives and send it over, but it'd be more interested to use recent mail.
Of course, as a byproduct of putting my address here, I'm sure to get actual spam as well. That'll help to see if their filters catch most of it. I expect they will.
Either way, I win. Well, okay, maybe "win" is too strong a word.
Comcast Cable and Internet Service Pricing
When I moved from my apartment into my townhouse a bit over a month ago, I called Comcast to let them know. I explained that I was merely relocating and didn't want to change any aspect of my service other than the location.
They said that was quite easy and we selected dates for the change. They told me to hang on to my existing cable modem. Then, on the appointed day, the Comcast tech came out to check signal levels. He said all was fine and that I shouldn't have any trouble getting decent TV and Internet signals to the various drops in the house.
I never got around to hooking up the TV. I haven't watched TV in about 6 weeks now and don't miss it at all. (Mental note: Sell Tivo soon and cancel service. Life's too short for TV.) I did try to hook up the old Netgear router I used at the old place, but it wasn't happy. I tried my notebooks and they couldn't get an IP address either. Since the DSL was working fine, I decided I'd screw with it later.
Then one day, about 2 weeks ago, I got a letter from an agency on behalf of comcast. They wanted my digital TV box back or $500. I called to explain that I never had one (with $13 basic service, what good would it have done me?). They realized that it was the cable modem and I explained that I was told to reuse it at the new place. They updated their records.
The, a few days ago, I got a bill from Comcast for $150. It said that I had not returned my cable modem. Sigh. I called them today and explained that I was told to keep it. They updated their records.
Then they asked if I wanted Internet service, which I thought was a pretty dumb question. It seems that they never actually transferred my Internet service. That explains why (1) I got no signal, and (2) I haven't been billed for it. A tech will be by tomorrow to hook me up after my dentist visit.
Speaking of billing, I asked about their pricing and found it quite amusing. I was interesting in canceling TV service (for which I pay roughly $13/month), since I'm not using it at all. Here's the breakdown of what Internet service costs in various scenarios.
| Own Modem | Rent Modem | |
| With Basic Cable | $42.95 | $45.95 |
| Without Basic Cable | $56.95 | $59.99 |
Needless to say, I might as well keep the TV service I'm not using. It's cheaper by a few cents.
Whatever.
Your Playlist is not Presence
One of the great features of Instant Messaging clients is that they provide an easy to use way of communicating presence: Out for a bit, Eating lunch, At work, On a conference call, Don't bug me, and so on.
But as of now, I count 4 different people on my buddy list who are using some sort of automated program to update their status every time their MP3 player switches to a new song.
Ugh.
I really don't care what you're listening to. If I did, I'd ask. I'd much rather know if you're available for an occasional question or interruption. But now if you wander off and leave your MP3 player running, I won't know that. Heck, even the IM client's built-in idle detection is probably fooled by this.
Maybe someone can clue me in a bit. Why do people do this? Do they think it makes them "cool" to abuse their status message with something that hides the info I'd probably want if I happened to look at their status? Or is there some "find the most annoying or useless way to screw with your IM status" contest going on?
April 19, 2004
High Performance MySQL (the book) is Shipping!
 As noted on our site for the book, O'Reilly brought the first copies to the 2004 MySQL User's Conference in Orlando and it had sold out by the middle of the second day.
As noted on our site for the book, O'Reilly brought the first copies to the 2004 MySQL User's Conference in Orlando and it had sold out by the middle of the second day.
Woohoo!
Now Amazon reports that the book is shipping in 1-2 weeks (rather than being pre-order), and we even have our first customer review posted too.
I read the front matter and first three chapters on the plane ride home last night, pen in hand. I didn't mark as much stuff as I expected to but did manage to find a couple of dumb things we may want to fix for subsequent printings.
Thanks to everyone who has pre-ordered a copy or bought one at the show. The response has been amazing so far!
Derek has a picture of the books for sale at the show booth. I'll link to it as soon as he posts the pics.
Update: Posted.
A Good Day of Soaring at Seminole Lake
Since Tuesday was a bust, I headed back to the Seminole Lake Gliderport on Saturday morning with plans to get a checkout early and then take their DG-300 up for some local soaring.
Area Checkout
I arrived a bit after 9:30 and met my instructor shortly after. Izumi (not sure on the spelling) was to fly with me in one of their Grob 103s for some local checkout flights.
After doing my pre-flight (the Grob was really showing its age and the fact that it's a club ship and trainer), we pulled out on the runway and prepared to launch. Their Pawnee had us in the air in no time and before long I was wondering how I would ever navigate the area without the aid of my handheld GPS.
After flying through numerous strong thermals (at 10:00am!!!), we released at 3,000 feet and I found our first thermal of the day a few moments later. Meanwhile, Izumi worked on orienting me to the area. He pointed out three landmarks that, it turned out, were quite sufficient for helping me find the airport later in the day. There was a decent sized aqua colored lake, a sand "factory", and the nearby highway.
I spent most of the next hour jumping from cloud to cloud to find the various thermals that kept us in the air. We chatted a bit about my flying experience and his. It turns out that he used to work out at Crazy Creek in northern California, so he was well aware of the conditions in Hollister and Truckee.
As it approached 11:00am, he told me to head back to the airport and show him a landing. I sped up and trying to find some sink to circle in. But after 5 minutes of that and loosing no more than 400 feet, I opted for the only sure way to get down: the spoilers.
Before long, I was down to pattern altitude (1,000) at the IP and headed in. I had to use spoilers through the entire pattern to counteract the lift we kept encountering.
I turned base at about 600 feet and final at 400. We landed near the main hangar and let the ship roll off just by the house. No problem. I asked how many more flights we wanted to do, expecting at least one more for pattern and landing or mayb e a rope break. But one was good enough, so we headed back to the office.
There I got a sign-off in my log book and worked on studying the DG-300 manual as well as the local sectional chart. Folks back at the office seemed amused by our hour long checkout flight. I guess 20-30 minutes is more common, but I just wasn't in a hurry to come down with such abundant lift. I'm really not used to releasing at 3,000 near the airport and staying up for an hour without trying very hard!
DG-300 Pre-Flight Activities
Around noon, I helped Ingrid move the DG-300 out of the hangar so that I could get comfortable with it. I tried out the parachute they had and spent some time getting comfortable in the cockpit. Since I had a handheld radio, we pulled the weak battery out so it could charge while I flew. That meant having no electronic variometer, I wasn't terribly worried about that. There were clouds everywhere, so finding the lift wasn't going to be rocket surgery.
After a bit, we pulled it down the launch area where Knut could give me a cockpit checkout. In doing so, we discovered something wrong with the tire on the main landing gear. It was slightly off the rim in one spot and rubbing another part of the gear. We showed Knut and he decided we should take it back to the Hangar so he could try to fix it.
We did. He jacked it up, let the air out, and made some adjustments. The problem seemed to be solved, but he expected that it'd happen again. He then went over the details of this particular ship with me and the other guy who was to fly after me. Neither of us had flown a DG-300 before and I had never flown a glider that used a CG hook rather than a nose hook. He advise me to launch with full forward trim and only let the glider fly with it was going fast enough and ready to fly.
DG-300 Flying
I launched a bit after 1:00pm and again towed to 3,000 feet, hitting several thermals along the way. 2,000 would have been quite sufficient. My takeoff was a bit shaky. At one point, I started to get out of position and was just about to release the line when the glider lifted off the ground. So I drifted back into position behind the towplane and all was well. Mostly.
Off tow, I pulled up the gear, trimmed the elevator, and worked on getting comfortable with how it flew. The parallelogram control sick felt a lot like the one in my 304C, and the trim worked like that in BASA's DG-1000.
Once comfortable, I worked on finding a thermal. I took my first lift to about 4,500 feet, jumped to a nearby cloud, and had fun for the next 2.25 hours. I never went far from the airport, but I had a blast. The highest I got was 6,000 (cloud base) and the lowest I ever got was about 3,800. Lift was quite abundant and quite strong in a few spots (8-10 knots at time, but 4-5 was far more common).
When it was [past] time to return to the field, I again had to resort to using the spoilers to get myself down. I entered the pattern at 1,100 feet over the IP and landed reasonably well considering the turbulence and crosswind I had to contend with. I came up about 300 feet short of where I planned to stop, but it turned out to be perfect for the next guy. I turned over the ship, snapped a few pictures, helped tow it back to the line, paid my bills, and headed back to the hotel.
All in all, I had an excellent day of soaring. Between the two flights, I logged nearly 3.5 hours and never had to worry about finding lift very much. The DG-300 was a fun ship to fly with no real surprises. Like other DG ships, the cockpit was quite comfortable--especially the headrest. I hope to back it back to Seminole Lake someday. The people are fantastic, the flying is quite affordable, and the conditions (at least in the springtime) couldn't be better.
April 18, 2004
Stuck at Orlando Intl without Wireless and My New Travel Rule
When are airports gonna figure this out? If you have wireless Internet service available in your terminals, people actually will pay for it. How hard is that to figure out, really?
Murphy has struck again. I dropped off my rental car 2 hours before the scheduled departure of my flight (as advised), got to the airport 7 minutes later, went through security in 5, took the mini-train to my terminal, and found that my flight is departing at 5:48pm instead of 5:18pm.
That's wonderful. Now I'm stuck in the terminal for nearly two and a half hours with little to do. I don't have so much spare time as to make it worth going somewhere else, and without wireless I cannot catch up on the stuff I hoped to.
Grr.
KisMac hasn't found any evidence of wireless, public or otherwise.
And don't even get me started by the phenomenal lack of power outlets. I'm sitting on the floor across from the airport Burger King because it's the only power I can find within 1,500 feet (no joke) of my gate. This means everyone walking by has to check out the guy typing some rant on his Powerbook with the iPod and N-Charge external battery pack charging.
Speaking of Burger King, the selection of food here is pretty awful. A bar, Burger King, and Cinnabon. That's it. Really. It's a good thing I had popcorn and a drink during the IMAX movie at the Kennedy Space Center a few hours ago. That was breakfast and lunch I suspect.
Making matters worse is that my connection in Dallas had originally allowed me about an hour. Guess what. Now it's about 30 minutes, assuming this flight leaves on time, encounters no delays getting to the runway, in flight, and landing in Dallas. To make it even more "amusing" my flight seems to be arriving at terminal C, while my flight from Dallas to San Jose is leaving from terminal A.
Great!
We have 30 minutes from landing to get to the gate, get off the plane (of course, I'm in the rear), get to the intra-terminal train, to my gate, and on the plane.
Anyone want to guess if both my luggage and I manage to make it?
Wait. Since there's no wireless here, I won't have time to post this before getting home. And since I'll be getting from gate to gate in Dallas, I can't post from there either.
New Travel Rule
In light of this and my trouble making a connections earlier, I've decided upon a new travel rule:
Never schedule flights that have a connection window of less than 90 minutes. Ever.
I'll have to be sure to pass that along to the professional travel agents at work (who booked this and many, many other flights). You'd think they're already be aware of the dangers in doing this, wouldn't you?
Yeah, so would I.
In the meantime, I guess I've got a tiny bit of e-mail to catch up on and a ton of people watching to do.
Yeay for me!!!
Not.
Later: I made it by 5 minutes... Time to post queued blog stuff.
A Brief Visit to the Kennedy Space Center
With nothing else to do before heading to the airport for my flight back home, I decided to head to the Kennedy Space Center. Well, this was after sleeping in too late (hey, it was only 7:00am in the Pacific time zone), packing, and checking out of the hotel.
My goal was to see one of the two IMAX movies that are showing there. (Exercise for the reader: try to find the show times in advance on their web site.) Based on a rough guess, I figured it'd take about an hour to get to the Kennedy Space Center Visitor's Center. So I headed over, following signs for KSC and/or Cape Canaveral.
Fifty-seven minutes later, I arrived at the Kennedy Space Center's Visitor Parking lot (which, amazingly, is free) and headed over to the ticket area. I got the cheapest possible ticket, since I didn't have any time for the bus tours (next time I visit, I guess). I then headed over to the line for the 1:00 showing of The Dream is Alive.
Visitors are advised to get in line 15 minutes before the show. I got in line at 12:40pm and was surprised to find that they open the doors at 12:45pm. I was nearly at the head of the line and managed to snag a prime seat--second row from the top, middle.
I've always been a sucker for both IMAX and any films related to the space program. As you can guess, I enjoyed the 40 minute show. It left enough time for me the swing by one of the two gift shops (talk about overkill) and grab a few t-shirts and mugs (the big kind, not for coffee). You see, I try to get a decent t-shirt and mug from every place I visit.
After that, I headed to the airport to begin the journey of getting home.
April 16, 2004
Blinded by Gmail's Gigabyte?
Okay, this is getting too stupid. Even Tim O'Reilly seems to be sucked in by Google's reality distortion field now. I guess they've been taking lessons from Steve Jobs, because Tim usually isn't this easily excited by non-innovation. (Or maybe Tim was an early investor in Google? Anyone know?)
Gmail is fascinating to me as a watershed event in the evolution of the internet. In a brilliant Copernican stroke, gmail turns everything on its head, rejecting the personal computer as the center of the computing universe, instead recognizing that applications revolve around the network as the planets revolve around the Sun. But Google and gmail go even further, making the network itself disappear into the universal virtual computer, the internet as operating system.
For god's sake, it's web mail with a really big quota!
Now maybe I'm missing something here. And if I am, I hope a Gmail tester or two will set me straight (I have not had the time I'd like to play with it, but I have heard from a few of those who have). Let me recount the "innovations" from Google's Gmail as I've heard them:
- Giving users a lot of space. Okay, this isn't rocket surgery. Disks have been getting cheaper for a long time now. Do you honestly expect to see other large (and even mid-tier) web mail providers not increasing their offerings to match or surpass those of Gmail? It seems like a no-brainer to me.
- Proving virtual folders, conversations, search-based message lists, or whatever you want to call them. So we've got threading (not new) plus virtual folders (not new) in a single mail interface. Well, stop the presses! It's amazing to think that no mail clients have offered this functionality in the last 5-7 years! Oh, wait. They have.
- Adding context-sensitive ads to your mail. Yippie! I'm gonna switch right away so I can start seeing SPAM that I cannot filter even in my previously non-spam mail. Sign me up!
Yup. I've come up with three things. Did I miss something? I must have, because Tim's convinced that this is very, very important but I'm just not seeing it.
I mean, it "turns everything on its head" right?
It feels very incremental to me, but this is supposed to be part of the big Internet OS In The Sky (the drum Tim's been beating for a few years now), but I haven't seen the API yet. Or the new services they're offering. Or a version that works in the [modern] browser I use.
Can we please tone down the hype a few notches and get back to thinking about services that actually offer something remarkable and innovative? Something with an API. And if we're going to beat the Internet OS horse drum some more, how about something that actually fits into what one might think of as an infrastructure service rather than an end-user application?
April 15, 2004
Introduction to the MySQL Administrator
Notes from the Introduction to the MySQL Administrator talk at the 2004 MySQL User's Conference...
(I initially wanted to go to the "High Availability Solutions with Databases" session, but it seems to be a big Sun product pitch. Bad move, Sun. You sessions should clearly state that they're heavily focusing on your solutions.)
Alfredo is walking thru the UI of the Administrator. It seems to be fully functional now on Windows, with Linux and Mac OS X lagging a bit behind. The gist of this is that the GUI tool removed the need to touch the my.cnf file as well as interacting with the MySQL command-line tool for most administrative operations (security/privileges, account management, schema changes, config changes, replication setup, and so on).
Documenting this in the second edition of the book will be a challenge, mainly because I find most GUI admin a bit tedious.
It's hoard to write a lot about this tool without screen shots, since it's clearly a very visual application. I am impressed with how far along the tool is both in terms of functionality and the user interface itself. This will go along way toward making MySQL more approachable to those who shun the command line.
Toolkits used on various platforms are... Windows: Delphi, Linux: GNOME/C++, Mac OS X: Cocoa.
Hmm. Short talk.
InnoDB Multiple Tablespaces and Compressed Tables
Notes from Heikki Tuuri's InnoDB Multiple Tablespaces and Compressed Tables talk at the 2004 MySQL User's Conference...
Heikki spent quite some time as an academic doing math and later computer science. He wrote the first line of code in 1994 and was trying to figure out why relational databases were so slow. Five years later he had 110,000 lines of code and could run a TPC-C benchmark. He met Monty in 2000. Work in the InnoDB/MySQL interface began shortly after and took about 6 months. First release in 2001.
Heikki owns the company (Innobase Oy) and he now has two employees. Pekka working on hot backup and Marko working on compressed table space development. A third guy will be coming on board soon as well. Innobase Oy is an OEM supplier for MySQL AB. They make money via hot backup licenses, royalty from MySQL licenses, and support contracts. The company is profitable.
Development slowed in 2003 because Heikki was dealing with new users, bug reports, and support contracts/questions. New hires will speed that up again.
Multiple tablespaces appeared in MySQL 4.1.1 (Dec 2003). Sponsored by RightNow Technologies of Montana. Each table can be stored in its own .ibd file rather than one massive tablespace.
To enable it, just add innodb_file_per_table to my.cnf and you're good to go. But you do still need one ibdata file for the data dictionary, undo logs (rollback segment), and so on.
If you later disable support for multiple tablespaces, InnoDB will continue to use the old files while putting new tables back in the single tablespace. InnoDB doesn't handle symlinked tables during an ALTER TABLE like MyISAM does. The new table will end up in the default location, not where the original table lived.
You cannot move .ibd files from one instance to another. The .ibd files contain transaction ids and log sequence numbers. You also cannot move tables around on the same machine. Instead, use RENAME TABLE (and maybe a symlinked directly) to accomplish it.
Interesting... for restoring an old version of a table, you can remove the current one using ALTER TABLE mytable DISCARD TABLESPACE and then ALTER TABLE mytable IMPORT TABLESPACE to restore the old one. But the table must be clean, meaning no uncommitted records, all buffered inserts must be done, and all delete marked records must have been purged.
Compressed table formats will help reduce the disk usage required to store data. NULLs will take no space, many of the length records have been removed, and they've added on-the-fly zip compression to further reduce space. The typical InnoDB user should see at least a 50% reduction in disk space usage.
Old tables will not be automatically converted to the new format. Pages will still be 16k, but most pages will end up as 8k on disk. They'll need some sort of compression prediction but are still hacking on that it seems.
They also are looking at in-memory compression so that more pages will fit in the buffer pool. (Nice!)
Upcoming features: linux async disk I/O (available in Linux 2.6) and on-line index generation without setting locks. Unknown ETA.
They've added automatic index generation on foreign keys (in case you forget to create them). This should be in 4.0.19, he thinks. Sounds like it'll be in the next 4.1.x release for sure.
MySQL Replication and Clustering
Notes from Brian's MySQL Replication and Clustering talk at the 2004 MySQL User's Conference...
3.23.xx had single threaded replication, 4.0 had dual-threads to implement read-ahead replication (trivia note: that was my idea). Understanding the control files: master.info, relay log, binary logs, etc.
Be careful of things that do not replicate properly, such as a UDF that generates random numbers. It's possible to have different storage engines on the master and slave.
Brian's slides are impossible to read if you're not in the first 4-6 rows. Doh!
When setting up replication, you need to make an initial snapshot of your master. Typical techniques covered (mysqldump, rsync/scp, mysqlhotcopy, etc). He doesn't mention mysqlsnapshot or flushing the binlog on the server (the common case). Weird.
Replication commands: SHOW SLAVE HOSTS, PURGE MASTER LOGS, RESET MASTER, SHOW MASTER STATUS, SHOW SLAVE STATUS, STOP SLAVE, START SLAVE, etc. When replication fails: mysqlbinlog, checking slave status, SET GLOBAL SQL_SLAVE_SKIP_COUNTER, etc. Hmm, he just confused removing the relay logs and removing the master.info file. Whoops.
Brian warns about shared-disk clustering with MyISAM tables. NFS bad. Very bad. You can do "clustering" with one master, many slaves. Works well for read-intensive applications that can tolerate a bit of latency. Not all can. Sometimes it's better to put up slaves that you can hammer on for reporting purposes, such as with real-time apache logging.
Now we're looking at what I call tiered replication (master to slave to many slaves). This keeps a burden off the master, but I'd argue the burden of replication is so low that it's a non-issue in most cases.
Multi-master replication. Hmm. Brian described a star replication topology that either can't work or he glossed over a couple of major points. I need to ask about that one. Circular replication is next. He didn't really warn about how fragile this is.
Okay, yeah. He did gloss over some stuff because MySQL can't do that out of the box.
Ahh, now he's explaining that replication is log-based. Should have done that much earlier on.
Replication in 5.0: it'll work with the cluster product correctly. All masters will get copies of the cluster inserts into their binlogs. Storage engine injectiion is coming too, meaning a custom engine can add stuff to the binlog. Row-based (or logic-based) replication will be coming as well, it seems.
Replication in 5.1: adding multiple threads to replication. That means a slave can have multiple IO threads. Hmm. Some details not clear. It seems to make use of multiple network paths. But I'm not sure how the binlogs get split out on the master.
More info on-line in the manual, mailing list, and so on.
April 14, 2004
MySQL Cluster High Availability Features
Notes from the MySQL Cluster High Availability Features talk at the 2004 MySQL User's Conference...
Redundancy between nodes via heartbeat. Redundancy between clusters via replication. In other words, NDB provides local and global redundancy. System recovery for a full-scale shutdown. Hot backup and restore. The architecture in general was designed to eliminate single points of failure.
Lots of diagrams illustrating recovery in various failure scenarios that I can't ASCII copy too easily. Doh!
Writing a Simple MySQL Storage Engine
Notes from Brian and Sergei's Storage MySQL Engine talk at the 2004 MySQL User's Conference...
Brian recently added a stubbed out storage engine (table handler) to the MySQL 4.1 source tree. He's going to demonstrate a CSV storage engine that he's written.
To write a storage engine, you need to implement about 15 functions. Basic ones: create(), open(), close(), delete_table(), and so on. Now looking at what it takes to implement a table scan (SELECT * FROM my_table).
Ugh, the wifi sucks in this room. I can't even get a copy of the slides right now. :-(
Brian's storage engine is named "Tina." Can you guess what his girlfriend's name is?
Looking at ha_tina.cc now.
Hm, this session really isn't that bloggable. Too much detail to capture here. I guess you need to go read the code.
Introduction to MySQL Cluster
Notes from the Introduction to MySQL Cluster talk at the 2004 MySQL User's Conference...
First we're seeing an overview of the NDB architecture. If you've never seen it before, think "Oracle RAC without shared storage" and you're 95% of the way there.
The core NDB engine is a new storage engine inside MySQL. It provides transactions, replication, on-line backups, crash recovery, hash and tree indexes, on-line index builds, auto-detection of a failed node and re-sync when it comes back up. There are rolling upgrades, which provide a way to upgrade things without a disruption of service.
Man, this would be a lot easier if I could draw ASCII art even half as fast as I can type. Oh, well.
The NDB code is in the MySQL 4.1 tree as of today.
History. During 1991-1996, the initial design, prototypes, and research were on-going. Most of the code today originates from 1996. First demo in 1997, and it just got better from there. 1.0 came out in April 2001 w/Perl DBI support. In 1.4 (2002), node recovery was completed. 2003 brought ODBC, on-line backup, unique indexes, and more. The most recent stuff are on-ling upgrades, ordered indexes, and MySQL integration.
Benchmarks on a 72 CPU SunFire box hit 380,000 write txns/sec and 1,500,000 read txns/sec. Nice! More numbers in the slides, but I can't type that fast.
The management server handles the configuration of the cluster (config file, commands (start backup), and so on). There's a C API to the management server. It'll be integrated into MySQL at some point. MySQL uses the NDB API to talk to the cluster for normal data operations. Even with MySQL as the front end to NDB, it's still possible to use the NDB API natively to talk to the cluster too.
The config file specifies transaction timeouts, buffer sizes, heartbeat timeouts, nodes involved, and so on. Messaging diagram I can't replicate. Same with diagram of hash-based table partitioning. On-line backup and restore diagram too.
Data access methods (low-level): primary key, full table scan, unique key, parallel range scan. MySQL hides this from us, but it's interesting anyway. If you're using the NDB API, you need to know this too.
There is always a primary key. Like BDB and InnoDB, it'll create one for you if you don't specify one. Unique indexes are hash indexes, implemented as a second table (funky). It looks like unique indexes are expensive in NDB sort of like the way that secondary indexes are in InnoDB (again, I can't replicate the diagram here).
Currently working on: remaining MySQL functionality in the engine, on-line create/drop index, cluster management from the MySQL API, MySQL replication for MySQL Cluster, on-line add/drop column. Row length limit is current ~8KB but that will change in the future.
Questions and answers now. Clearly some folks don't get it. Heh.
LiveJournal's MySQL Backend
Notes from Brad's Live Journal talk at the 2004 MySQL User's Conference...
Brad walks thru the evolution of LiveJournal from a small college project with one server to a large load-balanced multi-machine, replicated, and load balanced backend. The evolution looks like the sort of thing I've seen play out many times now.
He eventually hit the write wall on replication, so had to go from single master and many slaves to smaller clusters. Each user lives in their own cluster, which contains a master and several slaves. There was still a single "global cluster" that's used to map users to clusters. This scales much better.
This caused a few problems. Auto-increments were no longer globally unique. Each user needed their own number space. That makes it hard to migrate users to other clusters. They used multi-column primary keys to get around this.
LJ is always fighting a battle against I/O or CPU bottlenecks. They split MyISAM tables into multliple tables and databases to get a bit more concurrency.
Amusing machine names--mostly from South Park and various meats.
Eventually moved to a master-master setup to reduce the impact of having a so many single points of failure. This makes a lot of their maintenance easier. But they have to be careful of conflict resolution.
They use Akamai for static content (images, css, etc).
LiveJournal uses both InnoDB and MyISAM, picking the right one for the job and trying not to use any features specific to either one of 'em. Brad recommends designing for both. (I agree in some cases and disagree in others...)
Email done via Postfix + MySQL rather than static DBM files that need to be rebuilt. Each Postfix server gets its own MySQL install.
LJ logs apache in MySQL too. They use MyISAM and INSERT DELAYED with a big delayed insert buffer. Their proxy boxes use mod_proxy+mod_rewrite and mod_rewrite talks to an external program that's picking a server based on how busy the back end servers are.
Brad is writing a proxy in C# (for fun, apparently) to replace some of this, maybe.
Uses DBI::Role to get db handles in Perl.
LJ relies pretty heavily on caching nowadays. None of the stuff in MySQL was quite what they needed, so they built memcached. Used by LJ, Slashdot, Wikipedia, others use it now. Original version in Perl, now written in C. Lots of O(1) operations inside make it quite fast. The client can do multi-server parallel fetching (kick ass!). They run multiple instances on boxes with more than 4GB RAM. They have a 90-93% hit rate on the cache.
Sniffing the logs using Net::Pcap rather than having stop/start MySQL just to toggle logging. (Nice!)
Brad's slides are on-line.
MySQL/InnoDB Performance Talk
Some notes from Peter's MySQL/InnoDB Performance talk at the 2004 MySQL User's Conference...
DBT2 Benchmark, http://sf.net/projects/osdldbt.
He uses 2.4.21 kernel, no swap, and the ext3 filesystem. Runs benchmark, checks status output (SHOW STATUS or using mysqladmin), then begins tuning. First thing to do is enable the slow query log. Find queries in slow query log, run EXPLAIN on the slow queries, converting non-SELECTs to SEELCTs when needed. Index tweaking often follows. Check SHOW PROCESSLIST for slow queries too (I'd recommend using mytop for that, of course).
Adding many indexes is best done with ALTER TABLE rather than several ADD INDEX statements.
SHOW INNODB STATUS will give some insight into your disk I/O performance and then for tweaking the size of InnoDB's buffer pool. Then we turn to looking at the size of InnoDB's transaction log file. Increasing it will reduce the writes in many cases.
Audience question about why there are writes at all. Answer: the benchmark (TPC-like) simulates order processing, so there are writes happening. It's just that the test is supposed to have more reads than writes.
Next we're looking at Opened_tables to make sure the table_cache is large enough.
Set InnoDB's thread concurrency to (num_disks + num_cpus) * 2. Also look at increasing the size of the log buffer.
Now we're back to more index tuning--replacing an older primary key with a new one having re-ordered the columns in the index. Updating primary keys is bad because of record shuffling during those updates. And keep those PKs small!
Damn. That's it for now. I have to leave early for a meeting, so can't take notes for the full session.
MySQL at Sabre
Notes from Michael Benzinger's "MySQL at Sabre" talk at the 2004 MySQL Users Conference.
Sabre had been the reservation system for American Airlines. They're also the backend for Travelocity as well.
Cost was the primary motivation for moving to MySQL.
Session, shop, price, sell, fulfill is the model they follow. Finding best fares is apparent a very hard problem. Lots of interesting algorithms to find the best paths and lowest costs. They price roughly 250 tickets per second.
Shopping finds the low fares. Shopping scales horizontally quite well. Pricing is used to print the ticket. Pricing used to be done on mainframes. Many companies still use them, but Sabre doesn't anymore. They run Linux on HP/Intel boxes now. They started with HP's PA-RISC running HP/UX but HP/UX didn't run on Intanium yet. Now they have 45 4 CPU Linux boxes. 1.5GHz, 6MB, 32GB RAM for shopping servers.
They also use GodenGate's Extractor/Replicator. InnoDB, 50-60GB of data, real-time updates, MySQL 4.0.15.
Interesting architecture diagram that I can't easily replicate here.
Development costs are way down (50%). Run-time and operational costs are significantly lower now too. They wrote their own API wrapper in C++ and have a pre-compiler used to convert the SQL for the MySQL API.
In addition to shopping, they use MySQL elsewhere too. Site59.com uses it. They're working on data mining and setting up a cheap data mart.
April 13, 2004
Skittle Corpse
Consider this my contribution to the collection of search terms that, until ... a few days from now, had no results.
A few minutes ago I put a used (meaning "empty") skittles bag in the trash and quietly announced "skittle bag" to which Derek replied "skittle corpse" at which I laughed quite heartily.
That phrase is, in and of itself, not funny. What is funny is how my brain wasn't ready to hear it.
Well, okay. It's maybe a little funny.
Speaking of things my brain was not ready to hear, after the laughing fit (and subsequent Google searches for "skittle corpse" and variations of the phrase), Derek announced "it's a virgin corpse." But my brain's auto-complete feature heard "virgin" and had already filled in either "search" or "phrase" but was not at all prepared for hearing "corpse" next.
I'm not sure which is more funny now:
- skittle corpse
- virgin corpse
- blogging it
Speaking of blogging it, I had trouble remembering one minor detail and paused from my typing to ask Derek to confirm that I had, in fact, said "skittle bag" earlier. He did and then said, "I assume this is being documented for posterity."
I responded with the only appropriate answer:
How could I not?
Anyway, I can only imagine the sort of nutjobs that are going to end up on this weblog post after the googlebot has had a chance to suck it in.
Welcome to the 2004 MySQL Users Conference
 Well, as you can see, the registration desk is open for the 2004 MySQL User Conference. The conference begins tomorrow and runs thru Friday. I'll attempt to use the hotel's reasonably good wifi coverage to post occasional pictures and summaries of what's going on.
Well, as you can see, the registration desk is open for the 2004 MySQL User Conference. The conference begins tomorrow and runs thru Friday. I'll attempt to use the hotel's reasonably good wifi coverage to post occasional pictures and summaries of what's going on.
Well, if I have time. You can never tell at these things.
Anyway, if you want to follow along on that much of the action, I'll be posting everything to the MySQL category of my weblog. You might also check out the 2004 MySQL Users Conference blog aggregator that Mike Hillyer has set up. I'll try to ping it with all my stories too. I'll also try to post my pictures here as time and bandwidth allow.
If you're blogging the show too, be sure to ping http://www.vbmysql.com/uc2004/trackback.cgi/68 . And stop by to say hi. It's always good to meet fellow bloggers, readers, and other random strange people strangers at the show.
Sunshine State, My Ass!
 Last night it was rainy in Orlando. This morning I headed over to Seminole Lake Gliderport to see about at least flying an area check flight before things got going today. No such luck.
Last night it was rainy in Orlando. This morning I headed over to Seminole Lake Gliderport to see about at least flying an area check flight before things got going today. No such luck.
Cloud bases were at about 1,000 feet (pattern altitude) and there was a variable 5-15 knot west crosswind. It was better than when the alarm went off this morning and the wind was blowing by the hotel at about 25 knots. But still. I've seen the sun for a whopping 5 minutes so far.
Bah! We have more sunshine back in the Bay Area today I bet.
Oh, well. The weekend looks decent. I'll be back there to fly on Saturday morning. I hope to get my area check done early and then take up their DG-300 for a few hours. We'll see how it goes.
I did spend a few hours checking out the gliderport, walking the 3,000 ft bt 200 ft grass runway (a beautiful sight), taking pictures, and meeting some of the locals. I'll try to get the pics up later today.
Update: I've posted the pictures. Sorry, no captions yet. (I seem to never get around to it.)
April 12, 2004
Made it to Orlando and Flying Updates
American made me miss my connection in Dallas, but got me on another flight an hour later. I managed to find the car, find the hotel, find the room, find dinner, find and pickup Derek, and find a little grocery store.
Oh, and I found the free WiFi too. It mostly works.
The weather for tomorrow looks ungood for a day of soaring Florida. :-(
Speaking of flying, I finally updated my neglected flying blog, so you can see what the heck I've been up to (acro stuff, buying a glider, beginning cross-country, and so on).
Updated: I've posted pictures of my glider in Hollister, taken on the first day I flew it there.
Flying Update
Okay, it's been a long time since I've updated my flying blog, so I'm going to do so in one big entry. I'm on a flight to Orlando right now, so there's not a lot else to do anyway. :-)
New Toy
Since I last wrote, I've done quite a bit. First off, I bought a glider. My new toy is N304GT, a standard class Glasflugel 304C ship. I bought it from a guy down in Hemet, California about a month ago. Since then I've put about 8 flights and 10 hours on it--maybe more. The ship only had about 14 hours on it when I bought it, so it's barely been broken in yet. It still looks very new.
I'm quite happy with it so far. It flies very well. It's stable, easy to control, and very quiet when all the vents are closed. My first few flights were short hops to get used to the glider and make sure I knew how to land it. Strangely, my first two landings were my best so far. Since then I've had a few bouncing problems but I'm close to having them sorted out now. I just need to be more agressive with the spoilers and hold my flare better.
Pictures of the disassembly are here. The Toyota 4Runner you see in the pictures is the vehichle I bought to "support" the glider, namely to tow it and hold and haul around all the crap that goes with owning a glider.
Updated: I've posted pictures of my glider in Hollister, taken on the first day I flew it there.
Grob Rides
A few weeks ago, Kasia came to visit and we went up for a few rides in the Grob (36L). She took some nice pictures of the area. I enjoyed flying the Grob again. Even my backseat landings were pretty smooth.
Rolls in the Fox
I finally went up for a flight in the previously moentioned Fox with Drew. I wanted to get a feel for the ship and try out rolls. We took a 7,000 foot tow and I spent a bit of time testing the 45-to-45 roll rate, slow flight, and stalls. After getting comfrotable, it was time for the real fun. I asked Drew if he wanted to demonstrate or just talk me thru it. As usual, he opted to just talk me thru the process.
I dove down to pick up speed, leveled off around 95 knots (maybe 100?) and pulled the stick hard to the right. In not time we were inverted and rolling thru the second half of the manuver. It all happened very quickly and quite smoothly. As Drew suggested, I didn't even need to worry about the rudder.
We ended up a bit nose low on the first try, so he suggested I use a bit of forward stick pressue when we go inverted to keep the nose on the horizon. On the second attempt, I did just that. Almost. You see, I didn't know how much pressure to use and ended up pushing the nose up quite a bit. We ended the roll a bit nose high and bleeding off speed. But it wasn't bad for second attempt.
After that, Drew took the controls for a minute to impress someone he saw flying nearby in a Cessna. I don't know what exactly he did, but I remember going about 120 knots, then being inverted, pushing 2-3 negative Gs and then rolling back over. While it was pretty damned cool, it also made me feel a little sick, so I took it easy for the rest of the flight.
I'd like to go up in the fox again, but it suffered some in-flight damage recently. Steve was flying it a few weeks back, pulling about 4.5 - 5 Gs when the left spoiler sudden popped open. He managed to get it back on the ground safely, but the ship is going to be out for a while getting repaired.
Stuck in the Mud and a 2-33 Ride
A bit over a month ago, the weather wasn't being very helpful after a seminar. I took up Babu for a ride in the DG-1000. We had a fun flight, finding a bit of lift near the clouds. When it was time to land, we found the winds had shifted and everyone was using runway 13. That's rather unusual. When I came in to land, I aimed a bit short, so as not to get in the way of any gliders that wanted to launch. But I came in shorter than expected and couldn't make the turn off. So I did the next best thing (or so I thought). I exited the runway between two runway lights and brought the glider to a stop.
It wasn't until after I got out and looked to push the glider back onto the runway so we could move it that I noticed it was very muddy there. We managed to push it almost all 15 feet back to the runway when the main wheel got stuck in the mud. We tried to work it out but only made things worse. This was all while getting rained on, of course.
After a few more attempts, a few folks came by to help and suggested using the tow plane to pull it out. Cherokee 17 Whiskey came by and we hooked up. I was to "fly" the ship out of the mud. But we never got out.
At that point we got a good look at how bad things were. The main wheel as almost completely in a mud hole. We did the only thing we could at that point. After rounding up 7 or 8 guys, we got on the leading edge and lifted the glider out of the mud and back on to the runway. Then Russell towed it back with his truck while I walked the wing and laughed at myself for making such a mess.
The next day, I spent 1.5 hours cleaning all the mud off the tire, disc brake, and landing gear. Thanks to me, BASA now has one of those nice little hand pumped power sprayers. The good news is that no damage was done and I learned a good leason about turning off into the mud.
Panoche Run in the new Glider
A bit over a week ago (Friday the 2nd), the conditions looked good and I was reasonably comfortable in my new glider. So I decided to fly down to Panoche and see if I could get high enough to come back to Hollister without landing there. I was the first to launch that day, so I ended up being the "sniffer." I flew to EL1 and found spotty lift. I got word to the others on the ground and on the way, so they all towed to the lookout tower instead of EL1 and were a bit more successful than I was.
I never got back above 5,000 feet but I did learn about struggling to stay alive out there. Three or four times I was certain I had to land, so I worked my way closer to the strip, only to find a thermal that'd provide another 1,000 - 2,000 feet of altitude. A couple hours of hard thermallying work was starting to get to me, so I decided I should land to get a tow back.
Much to my delight, I was not the first person to land at Panoche that day. Tony in 1A landed about 30 minutes before me and Brett landed in 2BA not long after I got towed back out. My Panoche landing wasn't as good as it should have been. I had a decent left crosswind to contend with and I was landing over an obstacle--Tony and his glider. He landed very short and just stayed at the near end of the runway.
I flew back toward Hollister and arrived with lots of altitude to spare, so I headed over toward Santa Anna only to find Lance in 9JH at 6,000 feet and reporting decent lift. I hung out there for about half hour jumping into the lift and playing around a bit.
Hernandez and Back
This past Friday (the 9th), conditions once again looked excellent, so I headed down with plans to fly to Panoche. Having learned my lesson last time, I decided not to be the sniffer. Instead, Dave (in GJ) lead the way. He flew toward the cumulus that were forming near the lookout towers and reported lift. I followed not long after and had little trouble finding the lift with Dave and Pat (in 9JH) already down there. Lance followed along (in 2BA), having recently completed his BASA cross-country checkout with Harry.
For the next hour the clouds got better and better, eventually forming nice little streets. Darren and Matt appeared in the DG-1000 just before Lance and I talked about heading back home. I made it as far south as Hernandez. Lacne managed to go a few miles farther than I did.
We looked back to EL1 and noticed some very nice clouds there. I decided to load up on altitude and then make a run for EL1, hoping to get high enoug there for an easy glide home. The plan worked nicely. We spent about 15 minutes getting up to 9,000 feet and ran to EL1. There we loaded up to 9,200 and headed home with lots of altitude to spare. We detoured a bit along the way, looking for signs of lift near the Tin Roof and over Santa Ana. There was nothing to be found, so we headed in to land after burning off the rest of our altitude.
EL4 and Back in the Duo Discus
(This is mostly a cut-n-paste of the flight report I sent in two nights ago.)
On Saturday I had planned to fly with Jonathon Hughes in the BASA Grob as a novice pilot in the Hollister Legue XC race that Ramy's organizing again. During the morning pilot's meeting, Russell mentioned that the Duo was free ALL DAY.
I joked that we should take it instead of the Grob. Then I thought about it for a couple minutes and realized that it was a good idea. The Grob schedule was booked before and after us, so we switched. That freed up the Grob for Darren and Stan to fly to Panoche and return. (Something tells me that Stan doesn't go to Panoche often enough!)
Let's see if I get the details mostly right...
We launched in the Duo at about 12:30, roughly 3rd or 4th in line, and headed to EL1 where Hugo (today's sniffer) found decent lift. Hugo, Matt, and others got to 8,500 or so at EL1 but we had a lot of trouble getting above 7.500. We struggled there for an hour and both tried several times to break thru to the higher altitudes. It never happened, so we left EL1 at 7,500 (entering the race at 1:30) and headed to the lookout towers before EL2.
We found lift on the way to the towers and also found quite a bit of sink. We tried to get to EL2 but had a lot of sink, so headed back toward Panoche a bit and found lift along the ridge to the south. I worked that for a while and was quite pleased to find it getting stronger and stronger the higher we got. Eventually we got high enough to hit EL2. We found sink everywhere, but Jonathon persisted beyond the point when I would have gone to refuel again and nailed a good thermal. It was tight but going well. That got us high enough to fly over Hernandez and on to EL3 and eventually EL4.
Once we got to EL4, we had to decide if we were going to push on or head back. Not being well acclimated to long duration flights (but I'm getting better), I made the call to head back. Besdies, my butt was sore. Maybe the Duo needs more padding? (I sure don't!)
Anyway, from EL4, I headed back toward the south Panoche ridge and got a bit of lift along the way. And from there, I headed toward the lookout towers but stopped at EL2 for a really nice thermal. I saw the vario swing past 10 a couple times. In a few minutes we got up to 8,500 for an easy glide back to Hollister.
Our time for the EL4 course, I think, was 2 hours from leaving EL1 to crossing runway 24 at Hollister.
The day was a bit more challenging than I expected. Compared to yesterday, there were several differences:
- no clouds to mark lift
- fewer gliders over a larger area
- someone was watching me! :-)
- no audio vario (Hugo had the Duo's logger. I hope he made his 500k!)
- 20 meter gliders just aren't as responsive as 15 meter
But I had fun and learned a lot. I was impressed with the way Jonathon hooked a few thermals and got in 'em nice and tight. I was also proud of myself for not falling out of lift too often.
April 11, 2004
High Performance MySQL is Hot off the Press!
 If you happen to wander by The O'Reilly and Associates web site soon, you'll notice a new book featured in the "Hot off the Press" section of the home page:
If you happen to wander by The O'Reilly and Associates web site soon, you'll notice a new book featured in the "Hot off the Press" section of the home page:
High Performance MySQL is an insider's guide to the poorly documented issues of MySQL reliability, scalability, and performance. The book gives in-depth coverage of MySQL indexing and optimization so you can make better use of these key features. You'll learn practical replication, backup, and load-balancing strategies with information that goes beyond available tools to discuss their effects in real-life environments. And you'll learn the supporting techniques you need to carry out these tasks, including advanced configuration, benchmarking, and investigating logs. Sample Chapter 7, Replication, is available free online.
In related news, I got my first physical copy of the book today. (Had I gone to work on Friday, I would have had it then like Derek did.) Over on the High Performance MySQL weblog, you can read about the first review as well as other book news as it comes in.
I'm headed to the MySQL User Conference in Orlando for the week (and I almost have my slides done too!), so blogging will probably be light and MySQL related when it happens. Hopefully the WiFi is up and running well.
O'Reilly plans to have copies available at the conference. Why not join us in Orlando and get an autographed copy? You can buy one before they're available in stores! :-)
April 07, 2004
gzip vs. bzip2 vs. rzip
For a short article in the June issue of Linux Magazine, I needed to compare the relative performance of gzip, bzip2, and rzip.
I used a 180MB mbox file, consisting of my non-spam e-mail from last month. (I know, it's only one test and doesn't represent how the tools will work on other data sets.)
command cpu time new size ------- -------- -------- gzip 17.63 sec 87 MB gzip -9 23.26 sec 87 MB bzip2 -9 114.90 sec 76 MB rzip 57.00 sec 52 MB
It's interesting to note that gzip's default (-6) and "try hardest" (-9) resulted in less than a 1MB difference.
I won't spoil the article by telling you the rest of the story here (why you may or may not want to use a particular tool), but I thought the numbers alone were pretty interesting.
See Also
April 06, 2004
Amazon Sex Toys?
I have a sick mind. And I'm a visual person.
I was checking out something on Amazon and that stupid gold box in the upper right corner shook and caught my attention. For some reason I decided that I ought to see what was in it this time, not that I've ever found anything remotely interesting there before.
But, you know, there's always a first time...
The first item that came up... Well, let's just say it surprised me.
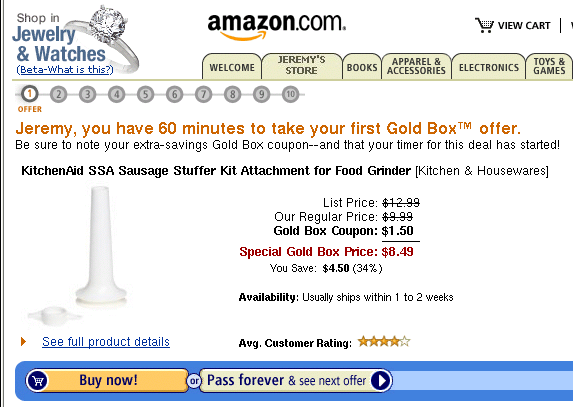
I glanced at it and thought, "What the...?!" and then I read the description: Sausage Stuffer Kit Attachment. That only made it all the more amusing.
I opted not to click on to the next item for fear of finding body oils or some other form of lubricant.
Anyway, I'll be staying out of the gold box from now on. It'll stay safely tucked under Mr. Bezos' bed. :-)
Now get your mind out of the gutter and get back to work! Just like I'm about to...
April 05, 2004
On-line Payment Insanity
You know, I really can't wait until all these stupid little on-line credit card payment systems just shrivel up and die, leaving the only logical players: Visa, Mastercard, Discover, and American Express.
I'm so sick of having to enter my credit card number into yet another system just to register a piece of $18 software.
God, haven't we cracked this nut yet? It's 2004 for god's sake!
Note to small software publishers. If you want my money, please make it easy for me to give it to you. Like most folks who've been buying small things on-line for the past FIVE YEARS or so, I have a PayPal account (not that I need one to let them handle a CC payment). Let me use that! I'm even willing to foot the processing costs just so I don't have to leave my credit card number it yet another database that'll probably get broken into later this year.
Seriously.
Why do we put up with this? And why haven't Visa, Mastercard, and the others managed to come up with a system that can be as ubiquitous and simple as the real world--you know where my card just works everywhere and I don't have to type it in every time?
If that's never gonna happen, what about just using Amazon.com's infrastructure? Then I could just 1-Click order the registration and let them handle it? That would still be so much better than what we've got today.
If this software wasn't so damned useful, I'd have given up when asked for my billing information for the billionth time and continued using my lame little Perl scripts.
April 03, 2004
Bloglines Feedback
As I mentioned a while ago, I'm now using Bloglines as my news/blogs/rss/etc aggregator. It took a bit of time to adjust to using the service, but overall I'm pretty happy with it so far. It has caused me to change the way I read in a few ways, but nothing earth shattering. And I've found a few minor annoyances along the way too.
Changes
First off, I had to adjust the way I update the blogroll on the right hand side of my main blog page. To do so, I slightly modified my opml2html.pl script and added a cron job to fetch my subscription list from Bloglines.
It looks something like this:
wget -q -O subs.opml http://www.bloglines.com/export?id=jzawodn
I love the fact that I can get at my subs via a simple REST interface without needing to jump thru cookie and/or authentication hoops.
Annoyances
A few things that bug me or I'd like to see changed...
- Sorting is very haphazard. I can sort my list of feeds alphabetically but then when I add a new one, I have to re-sort because it ends up at the end. Why not provide a default sort order?
- I'd like an option that hides feeds that have no new content since my last visit. That'd greatly reduce the scrolling I do.
- The unread counts aren't reliable. Sometimes it'll say "12" but when I click on the source I find that only 2 things have updated. I haven't quite found the pattern to what causes this yet.
- I'd like it to respond to what I do. My old aggregator would track the feeds I read most and sort them in that order. Bloglines could do the same thing. It turns out to be incredibly useful and I'm really starting to miss it. Implementing #2 would help, but it's not the same.
- I'd like to be able to toggle a "headline only" mode. It seems that 80% of the time, I want to read the full-post feeds I subscribe to, but 20% of the time I just want to skim headlines.
Disclaimer: Some of this stuff may actually exist and I simply haven't found it yet. If so, please let me know.
April 01, 2004
Patience
I kinda wondered how long it would take...
mysql> insert into foo_new select * from foo; Query OK, 60000000 rows affected (3 hours 3 min 52.94 sec) Records: 60000000 Duplicates: 0 Warnings: 0
Not bad.
(Note: Those are not actual table names.)
Google, I couldn't have drawn it better myself...
On this fine April 1st, Google brings us a visual representation of the accelerating decline of PageRank:
If only that image had existed a year ago. (Yes, that post is about one year old.)
On a related note, thanks to Google for making this year's April Fool's Day so damned entertaining on so many different levels. Keep up the excellent work and teasing.