September 30, 2003
Linkdump
Okay, here's a bunch of stuff I've managed to collect recently but don't have tons of time to blog about.
- I've recently become fond of the TV show "American Dreams." Derek reminded me that he blogged it a while back.
- Debian Backports - run that new stuff on an older system.
- XML Resume Library - write one resume, render it in many formats: text, pdf, html, etc. Cool stuff.
- Killing Comment Spam For Dummies - more good stuff from Jay
- JR on "off-sites", the latest management fad at work. Really.
- Kittie Porn. Really. It's okay to look.
- Incredible Adventures - maybe something to do for my next birthday (the big 3-0, ya know).
- A9 - the Amazon-backed search startup led by ex-Yahoo Chief Scientist Udi Manber. Udi's probably the smartest guy I've ever met.
- The Register: Google buys search engine - PageRank(tm) RIP?. They linked to me, so it's only fair to link back. :-)
- Shutterbug - a great photoblog.
There, I've flushed my buffer. I feel better now.
Damn, I love KQED
Al Franken is on City Arts & Lectures rignt now.
Kick Ass!
My pledge dollars at work...
We're All Smoking Crack in Silicon Valley (and Getting Rich)
Or that must be what it looks like to your average corn farmer in Nebraska.
 I don't read the financial media much, but having spent 3 years
working on Yahoo! Finance,
it's hard not to do so once in a while. I came across a story today
titled "Is
Google worth as much as Yahoo?" by Bambi Francisco (love that
name).
I don't read the financial media much, but having spent 3 years
working on Yahoo! Finance,
it's hard not to do so once in a while. I came across a story today
titled "Is
Google worth as much as Yahoo?" by Bambi Francisco (love that
name).
As is often the case with CBS MarketWatch stories, it goes into quite a bit more than the headline might lead you to believe. In this case, she spends some time discussing Google's self-appraised valuation of $17-$19 billion and then draws to a close with:
At the bandied-about price, Google would also be valued at a slight discount to Yahoo and possibly greater than Amazon.com. Both of those are arguably mature, established, not to mention older, companies with relatively proven track records.
And then she turns her focus to Friendster.
Google's outlandish valuation is likely why Friendster, the fast-growing online dating/social-networking company, is leaning towards accepting funds from blue chip venture capitalists rather than selling to the search company, according to those familiar with the situation. The word is that Friendster had conversations with Google to be bought out for about $30 million to $40 million in Google stock at an $18 billion market valuation for Google. At that price Friendster's upside may be limited, to say the least.
Of course, she reminds us that
Friendster has yet to post sales, much less a profit. Yet Friendster has apparently secured $13 million in funding, giving it a valuation of $53 million. Jonathan Abrams, Friendster's founder has not returned my call seeking comment.
If that seems a bit insane, we're reminded that:
InterActiveCorp's online dating services, including Match.com, Udate.com and Kiss.com, have 857,000 paying subscribers, as of the end of second quarter. IAC estimates that its online dating services will earn $38 million in cash flow this year, up from $28 million. Applying a 20 multiple on cash generated would give IAC's dating business practically an $800 million market cap, if it were a stand-alone company. This back-of-the-envelope-valuation exercise makes a potential market cap of $50 million for Friendster far more reasonable, say those familiar with the situation. That's because Match alone has 9 million subscribers (only some are paying subscribers) while Friendster has 2 million subscribers.
Valuations are funny things, aren't they?
[Disclaimer: I know several of the guys at Friendster, including Jonathan. I mean no disrespect. They're working hard to build a company and a service in shitty economic times. I just can't help but to be amused by this Google inspired flashback to the late 90s.]
September 29, 2003
Politicians and Weblogs: I couldn't care less...
<rant>With all due respect to Dave, who seems compelled to broadcast the arrival of every new political weblog, I really couldn't care less.
Actually, that's not true. I think that if I see another politician's face or campaign slogan on the front of a weblog, I'm gonna be sick. So I guess I do care. A little.
I really don't understand all the excitement. Another political candidate has decided to add "weblog" to the list of ways that he and his campaign staff can pollute our lives with more political bullshit. Yippie!!! As if that somehow validates or improves the image of weblog technology or the candidate.
Far from it.
Same shit, different medium.
Maybe the ratio of talk to action will someday improve in politics enough that I'd bother to pay attention, but I don't think an installation of MovableType and an RSS feed are going to do the trick.
No thanks.
What next, IM chat sessions with a candidate?
</rant>(Don't take this the wrong way, Dave. It's not you. It's the politicians.)
September 28, 2003
Blog Comment Spam on the Rise
Yesterday Jay noticed that I was having a comment spam problem. A few low-life moron assholes have been using my blog to try to boost the PageRank of their various businesses: search engine optimization, porn, and cheap prescription drugs.
He suggested that I look at his Killing Comment Spam Dead posting, which contains some very good ideas and pointers to prior art, such as queuing submissions, url matching blacklists, form tricks, and Mark's discussion of what most approaches suck.
After looking over it all and getting sick of censoring things myself, I'm not sure what I want do do about the problem. I've considered:
- turning off comments (bad)
- turning off comments after an entry is more than a few days old (might help, easy to do)
- sending confirmation URLs via e-mail to the poster (valid e-mail address required but not displayed on the site)
- writing a bit of content scanning code (there are certain features in common with all my comment spam)
- keeping all comments for each post in a separate file that's included at display time via an IFRAME or FRAME in the page. Then I'd drop in a robots.txt file that tells Google to ignore all comments. That'd defeat the spammer's main goal: higher PageRank.
But so far I haven't decided what to do. I'm inclined to try #2 and #3 but am still mulling things over and deleting 5-15 spams per day.
#5 is interesting and, to my knowledge, I'm the first to suggest it. Anyone else tried this yet? There are a few more tricky variations I'm thinking of too, such as noticing googlebot requests and feeding them slightly different content (hyperlinks stripped from comments, maybe?).
Would any of you frequent comment posters be offended by having to click a URL that arrived via e-mail to confirm your posting? What if you only had to do it once--ever? Think of it as lightweight semi-anonymous registration.
I'm not saying I'm gonna do it, but I clearly need to do something. I just need to figure out the right compromise between (1) keeping things free and open, (2) wasting my time, and (3) wasting your time.
Hmm.
Update: I've been using Jay Allen's cool MT-Blacklist for the last few weeks. It's not perfect, but it does 95% of what I need.
September 27, 2003
Tramp: Remote File Editing in Emacs
I just realized that one my favorite tools is something I've never written about here. If you're an Emacs user, there's a chance you're familiar with ange-ftp. It's an Emacs Lisp module that lets your browse remote FTP directories as if they were local filesystems. You can open, edit, save, and so on--never caring that the files are half way around the world.
In a world where I use secure methods (ssh, scp, and rsync over ssh) for remotely manipulating my files, ange-ftp isn't terribly useful anymore.
Tramp is the modern version of ange-ftp. It groks the tools I use. To quote the web site:
TRAMP stands for `Transparent Remote (file) Access, Multiple Protocol'. This package provides remote file editing, similar to Ange-FTP. The difference is that Ange-FTP uses FTP to transfer files between the local and the remote host, whereas TRAMP uses a combination of rsh and rcp or other work-alike programs, such as ssh/scp.
It's slick, seamless integration. In my ~/.emacs file I have:
(require 'tramp) (setq tramp-default-method "scp")
And then if I want to open a file remotely, I simple ask emacs to open:
/myserver:public_html/foo.html
Or, to fully qualify things and illustrate the syntax a bit more, I can use:
/jeremy.zawodny.com:/home/jzawodn/public_html/foo.html
And emacs does what I expect in either case. Tramp handles all the details behind the scenes. It's really quite handy.
All Praise Tivo!
 My Tivo
knows me too well. It recorded War Games, apparently
earlier today.
My Tivo
knows me too well. It recorded War Games, apparently
earlier today.
Despite the facts that I have it on DVD and VHS, I've seen it over 50 times, there are commercials in this version and the language has been slightly altered, I'm watching it anyway. How could I resist such a classic hacker film?
I mean... really?
Mailman infinite loop problem
For some reason, my Mailman install has developed a bug that causes it to enter an infinite loop, consuming all available CPU time. Forever.
It seems that others have seen this too and their solution works for me until it's fixed:
sudo /etc/init.d/mailman stop sudo rm /var/lib/mailman/qfiles/*/* sudo /etc/init.d/mailman start
Oh, well. Free software does that sometimes.
September 26, 2003
Why Can't Dell Innovate?
Steven says:
Dell today issued a press release announcing their intention to rip off every single good idea Apple has had over the last year or so. This annoys me so much. It sucks to innovate the way Apple does because a hundred other companies are always waiting in the wings to see how well you do, and then flood the market with cheap knock-off crap if it looks like you had a good idea.
Yup. It's really quite lame. These companies must be run by some of the dumb jocks from high school that never seemed to have an original idea.
September 25, 2003
Time or Attention?
I was driving to a meeting today when I came to an odd realization. Often times we (or at least *I*) think about things in terms of "do I have time to do this, or do I have time to do that?" But it's really not about time--at least not for me. It's about attention. Or maybe focus?
I used to think that people who said "I don't have time to do that" were just trying to sound technical in saying they had no time. But the more I think about it, I think that at least some of them suffer from a lack of attention bandwidth, not time.
At least that's how I feel much of the time. It seems that the amount of stuff I can assimilate, accomplish, and otherwise occupy myself with in a productive way is limited by my ability to deal with it all, not hours in the day/week/month. For example, I often end up screwing around doing useless stuff when I have more pressing things to attend to.
And I've always had too many things that I wanted to get into. Lots of stuff interests me. It's been like this since college. But even if I had time, I just don't think I could do it all.
September 24, 2003
Tivo Upgrade/Hacker Recommendation Needed
I have an original Phillips HDR112 Tivo that I'd like to have the following done to:
- Add a second hard disk: 120GB or so
- Double the RAM
- Add a network (Ethernet or WiFi) card
- Install hacks so I can telnet/ssh in, use a web interface, etc
And I don't want to do to it myself. Actually, that's not true. I'd love to do it, but I don't have the time. Can anyone recommend a place I can ship it to get all this stuff done, or someone in The Bay Area who does this sorta stuff as a side gig?
I'd obviously prefer someone local and will even buy all the parts in advance for that person if I'm told what I need to buy.
I've found a few places on-line that do some of this, but so far none do it all. And I'd rather not spend forever looking either.
Leads, anyone?
September 22, 2003
The Power of a Weblog
One thing has become quite clear to me in the last week, but I hadn't been sufficiently motivated to write anything about it until now. It's a revelation I had recently. One that should have come about 14 months ago when Jon Udell first suggested I "get involved" in the weblog community. Jon's always had the ability to see these things before most of us, so I don't feel so bad.
Anyway, it had absolutely nothing to do with the technology. It was this simple realization:
Weblogs are powerful.
Yup, that's it.
The Bad
By "powerful" I don't necessarily mean "good." There are times when weblogs have negative consequences in addition to the positive ones we normally associate with blogging. Take for example, the fact that Chi-Chu Tschang was fired from Bloomberg for his blog (thanks to Dan Gillmor, another journalist blogger, for the pointer).
And even though I've not discussed it before and will not go into any detail, suffice it to say that people at work have noticed my blog on more than one occasion. While there weren't happy about it, they had the integrity to bring it up with me.
It's no coincidence that roughly 6 months ago, In a post titled "Would you change your blogging habits if..." I wrote:
Would you blog differently? Shy away from criticizing your employer? Purposely avoid work-related topics?
The most interesting responses that post generated were those that arrived via private e-mail, never to be posted in a public forum. There were some compelling, surprising, and even scary stories.
What's that old saying?
With power comes responsibility.
Yup, that's it.
The Good
Despite the occasional work vs. blog conflicts that may arise, weblogs are generally quite positive. The good outweighs the bad 95% of the time. They open up so many doors.
I can no longer keep track of the number of great people I've "met" as the result of having a weblog. I can no longer count the number of times someone I've met at work, a conference, or even the gliderport who said "Hey, I read your blog!" I have no idea how many times a post on someone's blog has taught me something important or saved me countless hours of time.
Over the last year, I've seen many of my friends and co-workers start weblogs of their own. A surprisingly high percentage of them have stuck with it and appear to also be reaping benefits.
It's really quite amazing, now that I think about it. And looking ahead to the next 12-18 months, I only see it getting better and better. Services like TypePad are coming on-line to bring a whole new class of users (the non-geeks) into the fold. It's just going to get easier and easier to mine the riches of the social networks we're building.
Of course, the fact that you're even reading this probably means I'm preaching to the choir.
Life's funny that way.
September 21, 2003
The Million Dollar Keyboard
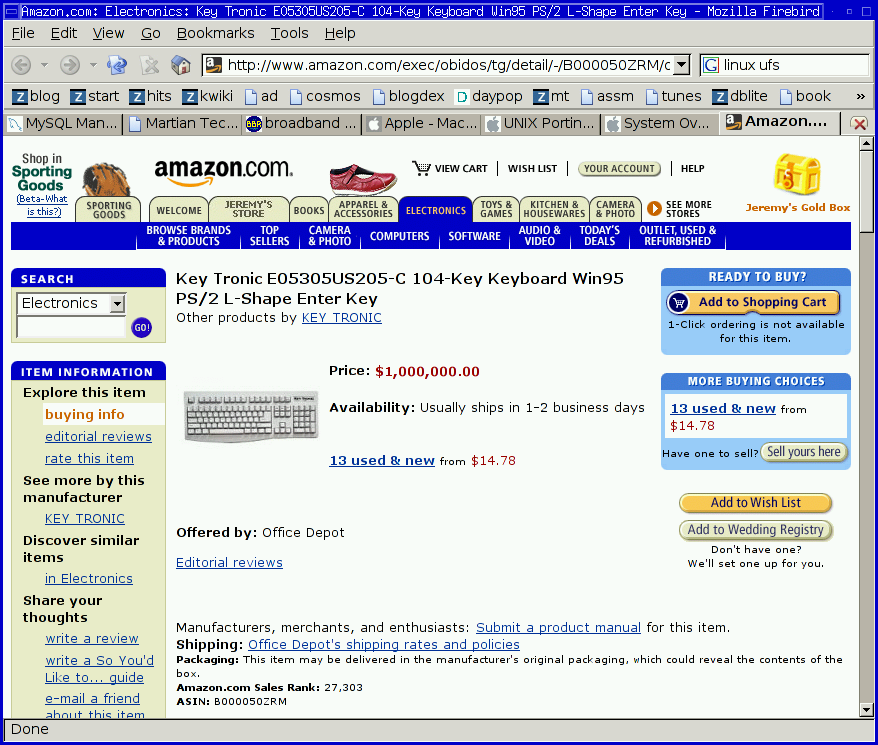 Wow, this is truly
amazing. According to the comments on this
keyboard, it not only has a key that will summon Jesus himself,
but it also cures cancer!
Wow, this is truly
amazing. According to the comments on this
keyboard, it not only has a key that will summon Jesus himself,
but it also cures cancer!
Apparently, there's good news for those of us without the extra million dollars laying around. They're available used starting from $14.78.
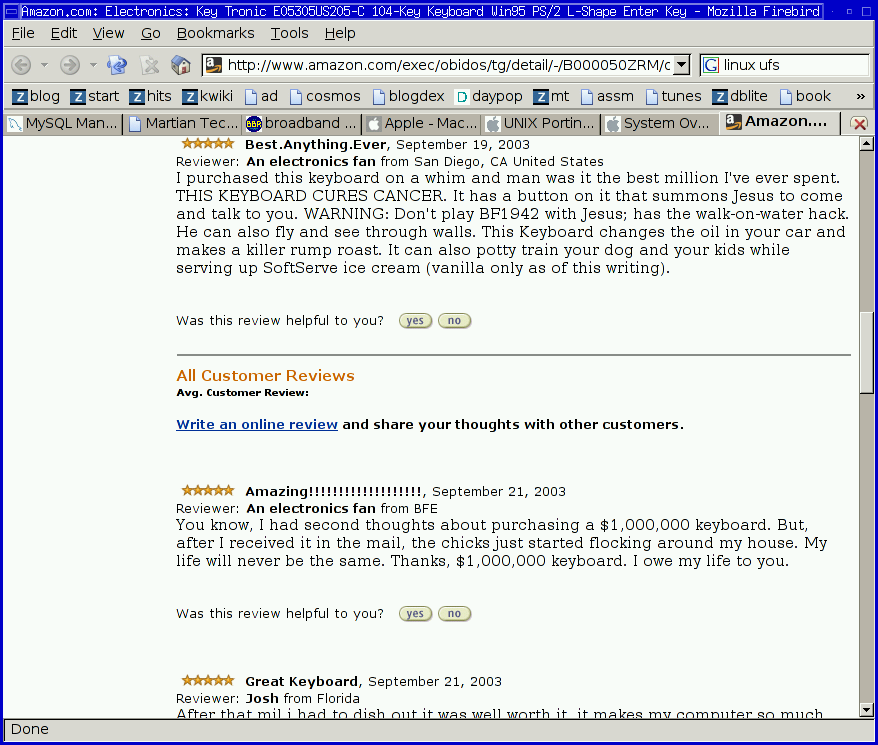
Note: The page may be fixed by the time you look. Amazon is aware of the "problem." Just in case, here's a full screenshot and here's one with the first few comments.
{kind=link}
Today's Random Blog Quotes
Philip Greenspun says:
A project done in Java will cost 5 times as much, take twice as long, and be harder to maintain than a project done in a scripting language such as PHP or Perl.
Jon Udell (in Infoworld) says:
In software development as in science, breakthroughs often occur when insights flow across disciplinary boundaries. The conductors of these flows are typically generalists who belong to several (or many) communities and who form bridges among them.
There were a few others, but I've managed to lose them. Doh!
September 18, 2003
Silly Recuiters
This is an amusing story. But to protect the guilty (and innocent) I'm not going to use real names. Otherwise regular readers of my blog would easily identify a few of 'em. I'll begin with the cast of characters:
- TechCompany: a well-known technology company that's hiring software engineers. (No, it's not the company I work for.)
- TechCompanyRecruiter: self-explanatory, right?
- OtherTechCompany: another well-known tech company. HappyFriend, HappyHacker, and UnhappyHacker have all worked there at some point. HappyHacker still does.
- HappyHacker: currently employed at OtherTechCompany.
- UnhappyHacker: currently not employed at either TechCompany or OtherTechCompany but job hunting. Would like to work at TechCompany.
- HappyFriend: a friend of UnhappyHacker and HappyHacker, currently employed at TechCompany.
Recently, HappyFriend thought "Gee, I'd like to get UnhappyHacker and HappyHacker jobs here. I'll submit their resumes for jobs and see what happens."
Well, as it happens, their resumes were under consideration for the same position. HappyHacker and UnhappyHacker discussed this before their interviews. There was no secret.
UnhappyHacker went first. There was a few rounds of phone screening and UnhappyHacker was ultimately told something like "sorry, we're not hiring for that position anymore."
This occurred roughly one day before HappyHacker was to begin a round of phone screening. HappyHacker thought it was odd that TechCompany would say that and not cancel the upcoming call. So HappyHacker decided to mail the person at TechCompany who was set to conduct the interview, asking something like "I guess we'll be talking in more general terms, since I understand that you're no longer hiring for the position we were supposed to discuss."
On the day of HappyHacker's phone screening, no word had come back from TechCompany. So the screening occurred and went quite well. The questions were basic and HappyHacker had no trouble with them. It went well. At the end of the discussion, the topic came up. The interviewer asked why HappyHacker thought the position was filled. HappyHacker explained that a friend (UnhappyHacker) had recently interviewed and was told that. The interviewer asked who it was. When the answer came, he realized that he'd interviewed UnhappyHacker. He said that his interview with UnhappyHacker had gone quite well and that he recommended UnhappyHacker with a thumbs-up.
HappyHacker relayed this info to UnhappyHacker (who was very interested in the findings, of course) in nearly real-time, thanks to instant messaging. After a bit of discussion, UnhappyHacker decided to e-mail TechCompanyRecruiter to ask for clarification. UnhappyHacker included the information that a friend (HappyHacker) had just interviewed and been told that the job was, indeed, open.
TechCompanyRecruiter responded that she'd look into it. No further communication has come from TechCompanyRecruiter.
Meanwhile, HappyHacker tells HappyFriend (via IM): "Hey, your recruiter people are funny. Here's what they did..." and explained the story. HappyFriend was then upset (rightfully so) that TechCompanyRecruiter either lied or genuinely screwed up. When HappyFriend asked TechCompanyRecruiter why UnhappyHacker was turned away, the response was roughly "we were looking for someone with more experience."
Strangely, nobody told UnhappyHacker. Furthermore, HappyHacker and UnhappyHacker have similar levels of experience (at least where it's relevant to this particular job). So one wonders if TechCompany will make the same "mistake" again.
The moral of this story, if there is one, probably goes something like this: It's a bad idea to lie to job candidates. And don't assume that candidates don't talk to each other. Assume they do.
September 17, 2003
I feel so dirty...
I picked this up in another story about Verisign fucking the Internet:
Two companies with ties to Yahoo Inc. are providing the technology and advertising know-how to drive the new VeriSign service. Inktomi Corp., a search technology company acquired by Yahoo in March, is one partner, while Pasadena, Calif.-based Overture Services Inc., a major provider of paid placement services, is the other. Yahoo announced its intent to acquire Overture in July.
Oh, great.
I wonder who we're supposed to slap around here...
Where's that "Proud to be a Yahoo!" t-shirt when you want to burn it, anyway?
In related news, run this search on Verisign's SiteFinder. Heh.
September 16, 2003
IT Job Security
If you're looking for an IT job that won't likely be subject to cutbacks anytime soon, I have a suggestion. Go work at Microsoft. In the group that writes their security bulletins and advisories. That's gotta be a pretty secure job nowadays, huh?
September 15, 2003
Verisign is Pure Evil
In case you didn't see the news on Slashdot (I didn't--someone had to tell me), it seems that Verisign has decided to demonstrate their evil in a way that I thought only Microsoft would:
As of a little while ago (it is around 7:45 PM US Eastern on Mon 15 Sep 2003 as I write this), VeriSign added a wildcard A record to the .COM and .NET TLD DNS zones. The IP address returned is 64.94.110.11, which reverses to sitefinder.verisign.com. What that means in plain English is that most mis-typed domain names that would formerly have resulted in a helpful error message now results in a VeriSign advertising opportunity. For example, if my domain name was 'somecompany.com,' and somebody typed 'soemcompany.com' by mistake, they would get VeriSign's advertising.
Okay, everyone. Let's all say it together: Fuck Verisign!
In case you haven't already done so, now would be an excellent time to move your domains to a more sensible registrar. I moved all mine to OpenSRS a while ago and have never looked back.
Consider making an appropriate entry for 64.94.110.11 in your routing table and/or firewall.
Some are reporting that not all the root severs have the wildcard yet. I found that it worked sometimes but not others.
See Also: I feel so dirty...
September 14, 2003
Scrmabeld Txet
Thanks to jwz for pointing out this excellent script.
I foresee amusing uses when combined with my innate ability to mistype things. Perhaps it'll do a decent job of fixing my mistakes?
Or, maybe I should have said:
I fsoeere ausimng uses when cbnieomd wtih my iannte abltiiy to mtyispe tgnhis. Ppehras it'll do a deecnt job of fiinxg my mskeiats?
Heh.
Partially Sighted
 While exiting the back seat
of a Cessna 182 on Saturday
morning, a bad thing happened. I was carrying my camera, GPS, water
bottle, and a piece of laminated paper (local map with specific
airports marked). A gust of wind caught the paper and managed to
sneak the corner up under my glasses and into my left eye.
While exiting the back seat
of a Cessna 182 on Saturday
morning, a bad thing happened. I was carrying my camera, GPS, water
bottle, and a piece of laminated paper (local map with specific
airports marked). A gust of wind caught the paper and managed to
sneak the corner up under my glasses and into my left eye.
Aside from the obvious pain, I noticed something else within a minute or so. My vision was blurry. It didn't take long to realize that the piece of paper must have scratched the surface of my eye.
The rest of the day was a real challenge. While it was rather blurry, my brain seemed to do okay if there wasn't a significant light contrast in what I was looking at. But if I looked at a something shiny and reflective, it was too much.
The drive home from the airport was difficult, given what a sunny day it was. But I made it and spent the rest of the day trying not to look at anything and wondering if it would heal itself.
When I woke up this morning, I was pleasantly surprised to find that my left eye's vision is only half as bad as it was on Saturday. I can actually read text on a computer screen today.
The obvious solution to working in this impaired state is to use my right eye only. Except that my right eye has always been the weaker of my two eyes. And my brain knows this. That makes it very hard to keep my left eye closed and get any serious amount of work done.
There's a first time for everything, I guess.
September 12, 2003
RSS Auto-Discovery 2.0
As I've noted recently, I've been playing (and fighting) with RSS Discovery issues.
It has occurred to me that there's some non-existent infrastructure that we (whoever "we" really is) need to build if RSS is going to really, really take off the way it should. The first piece of it builds on existing work, while the second is relatively uncharted territory as far as I can tell. And I'll only touch on it briefly at the end of this post.
Today
The current breed of RSS Auto-Discovery is quite handy and simple. By embedding this bit of XML:
<link rel="alternate" type="application/rss+xml" title="RSS" href="http://jeremy.zawodny.com/blog/index.rdf">In my blog home page, I'm advertising to aggregators and other software tools that there's a feed available for their use. They don't have to do any guesswork or check all the links on my page or look for the little orange XML button like a human might. For automated tools, that's great. The user goes to my blog home page and clicks a "Subscribe" button in their aggregator (or maybe uses a bookmarklet) and the computer does all the hard work.
This works really well for blogs. Many blogging tools seem to be providing it by default now. But RSS is ultimately about more than blogs, right? At Yahoo, we've begun to provide RSS feeds for Yahoo! News (info), Ask Yahoo! (no info page, feed here), and Yahoo! Buzz (info page). And there's more RSS to come.
If you look under the covers, you'll find the necessary <link> tag in various places. Like on the Technology News page:
<link rel="alternate" type="application/rss+xml" title="RSS" href="http://rss.news.yahoo.com/rss/tech">But let's think about this from the point of view of someone writing aggregation software that wants the user to understand nothing about RSS and little if anything about the structure of a site like Y! News. Notice that the tag is not on every story page, like this one. (Maybe it should be?)
Tomorrow
Keeping track of all that is going to become difficult as RSS goes more and more mainstream. We can't expect users like my Dad to know they're supposed to "subscribe" on the category page but not from the article pages. We can't expect them to know that there's even a difference, really. Nor can we expect software to figure this out--yet. And we can't expect news aggregators to add a whole category just for Yahoo content to their default feed list. That'd be crazy for a number of presumably obvious reasons. We can't expect users to run a web search for "Yahoo RSS" and end up on my blog. Remember, users won't know what RSS is. So the tools have to be able to figure out that Yahoo offers several categories of RSS feeds (News, Buzz, etc.) and many feeds within each of them.
We need more than what today's auto-discovery provides. And before you start think that this is just a Yahoo problem, consider News.com. On their pages (like this one) they provide the orange XML button but no auto-discovery support. I suspect that if a better solution was available, someone could convince them to use it too. After all, the more widespread their headlines are distributed, the more traffic (and presumably money) they get. Like Yahoo, they have a complex offering of content from a discovery point of view.
Proposal
What we need is "RSS Auto-Discovery 2.0." At least that's what I'm calling it.
What is it? It's a bit more infrastructure that could go a long way toward scaling RSS for big sites and making the aggregators job easier. It should solve the problems I tried to introduce above.
I don't claim to have this all figured out--at least not exactly. But some of us at Yahoo think this is an important problem. And we'd like to see it solved. Soon. But rather than dictate how we (or *I*) think it ought to work, let's come up with something that will work. You know, an on-line group effort but without all the politics. Can we do that? I hope so.
Having said that, I do have some ideas that I'd like to start with--in the hopes that a productive discussion will follow.
I think this is all pointing at a per-site machine-readable directory of the available RSS feeds. And the obvious format for that directory is OPML. It seems that most aggregators have settled on it as the de-facto standard for subscription interchange. And some even use it as their native "database" format.
So let's use it. I've talked with Dave Winer and he agrees that it's a sensible use of OPML.
Now, how might automated tools learn of the existence of this directory? I see two obvious ways that could happen.
- The file, like /robots.txt could reside at a well known location with a well known name, say /feeds.opml or /rss.opml? This has the advantage of being very simple.
- We add a new, optional <link> tag that tells tools where they can find a relevant OPML file that contains information about the various feeds offered. This has the advantage of being like what we do today and it provides a bit of flexibility.
There was a more complex variation that I've omitted. Why complicate something more than it needs to be? That's a compelling argument in my book.
Starting from here, where do we go next? Discuss here? On the syndication list? Or the aggregators list? Or on a Wiki?
Update: Mark Fletcher (of Bloglines) suggests that we need a machine readable way to specify a blogroll (in OPML, I'd assume). I completely agree. Any other meta-data we're missing today?
Update #2: Diego Doval has mockups in RSS and OPML.
What else?
Oh, yeah. I said there was a second thing, didn't I?
After this issue fizzles out, maybe we can move on to solving the next problem: Machine Readable Licenses for RSS feeds. This was partly prompted by Derek's Syndication vs. Aggregation post a few weeks ago. We had a few IM discussions about this, but it really is something that we need to resolve in a standard and machine-readable way. There needs to be a tag or link that means "you can syndicate this, but you absolutely cannot charge a fee" or whatever.
It's a can of worms, I'm sure.
I've Reverted
To my natural state, apparently.
For whatever reason, I haven't managed to get to bed before 2am for a single day this week. And one day it was 3:30am when I hit the sack.
Needless to say, I'm a night person.
On the plus side, I've still been getting up at a decent hour. But instead of heading to work, I've been working from home in the AM and then heading to work around noonish. It seems to be working out very well. It's a good compromise between the productivity of being at home where it's quiet and the necessary face-to-face interaction of being in the office.
September 11, 2003
Google Copycat
Interesting. It seems that Google is testing Related Searches on their site. That's so nice of them, copying something we launched on Yahoo Search about 6 months ago.
Of course, I'm biased. I wrote the first production version of the system that built the lists of related terms, fine tuned it, and whatnot. It was a pain in the ass for various reasons, but hey, it was innovative, right? :-)
Wow, and all this time later, the Search Easter Egg still lives.
Oh, another interesting tidbit. In roughly 6 months, the core code has gone from Perl to Java and is now C++. Heh.
September 09, 2003
More RSS Hacking
I've finally gotten back to the RSS autodiscovery work that I mentioned a few weeks ago.
Since then, I've scrapped all my code and started over. I'm not relying on third party code to parse RSS, HTML, or XML anymore. I just began coding up support for the most common cases and things have taken off. The code can reliably find the RSS feed for nearly every blog on my blogroll.
Very cool. It's not quite the hell I thought it'd be. And it took far less code that expected. I'm not done by any means, but it's a good start.
There are a few notable exceptions, of course. Blogs that don't support autodiscovery and don't point to any obvious looking files. And Slashdot. I have no idea how this happened, but they missed the "http:" portion of the URL! Seriously. Their HTML says:
<LINK REL="alternate" TITLE="Slashdot RSS" HREF="//slashdot.org/index.rss" TYPE="application/rss+xml">
Anyway... Other than a few anomalies it's not bad. Tomorrow I'll try much harder to find odd cases for it to cope with. I'd like to see my test suite go from 15 sites to about 50 or 80 representative URLs.
It's fun to code once in a while. :-)
September 08, 2003
Next time I'll call Dell
I'm so fucking sick of the PC Hardware industry.
Since I started mucking with PCs a long time ago, I've been a fan of ordering parts and building my own systems. And when it came time to upgrade, I'd do it myself.
Screw that.
After having built roughly 15 computers in the past 15 years or so (some for me, some for friends/family), I give up. I don't have time for the inevitable bullshit that comes with realizing that something just isn't working right--both in the hardware itself and the associated software and drivers. It's really, really, really not worth it.
What prompted this, you wonder?
I've wasted an entire damned day doing what should have been a trivial upgrade. I recently sold my venerable ThinkPad 600E to a friend. And I found another to buy the guts of my P3-866 desktop machine at work (the one that I brought in, not the one Yahoo supplies--long story). Anyway, with the combined funds I planned to upgrade the guts of that desktop a bit.
The Story
A week or so ago, the new parts arrived: a Pentium 4 2.4GHz processor, 1GB of 400MHz RAM (2 512 DIMMs), and an Intel D865PERL motherboard.
Yesterday I went to work in the morning to help with a database server switch. After that was done, I headed over to my desk to perform the swap. I had brought in one of my two LCD monitors and planned to just leave it at work where it'll get more use. That was roughly 10:30am. Six hours later, I felt a lot like Mark Pilgrim trying to install Windows XP.
I removed the old motherboard, leaving the CPU, fan, and RAM installed. I figure I'll just ship it to Andy that way. I installed the new motherboard, RAM, and CPU. But when I powered it up, it didn't do much. The CPU fan came on and a few things lit up on the motherboard, but the hard disk didn't spin at all.
So far it was pretty much in line with my expectations. I've never (and I mean never) had a motherboard work on the first try. So I carefully reseated everything, looked for shorts, etc. No dice.
Figuring there might be some useful on-screen info, I decided to plug in the video card. But I couldn't. My old AGP card (a 3dfx Voodoo 3 3000) didn't fit. Okay, something was weird. The AGP connector looked as if it had been mounted backwards on the board. The little piece of plastic in the socket that's there to make sure you only plug the card in the right way appeared to be in the wrong place.
I double-checked the little picture of the motherboard. Yup, it says "AGP" there, so this is where the video card goes. Considering that all the other slots are PCI slots, there wasn't a lot choice in the matter.
At noon I decided to head home, taking all the pieces and parts with me. I have a few spare video cards in my collection and I figured something would fit.
Ha!
All my other cards had the same problem. So I headed over to Intel's web site and looked more closely at the product specs. The pictures that Intel provides told me that the socket on my board was certainly not on backwards. Then I noticed that it had a "Universal 0.8/1.5 V AGP 3.0 connector (with integrated retention mechanism) supporting 4x and 8x AGP cards."
Hmm. I don't think AGP 4x even existed when I got my Voodoo several years back. And something told me that "universal" doesn't mean what I thought it should...
Crap!
A visit to Fry's
I headed off to Fry's in search of a cheap video card that was fancy enough to work in the motherboard and which came from a vendor that had decent XFree86 support.
After a bit of browsing, I settled on an ATI Radeon 9200. It wasn't the absolute cheapest but at ~$120 it was much cheaper than most of the apparently high-end cards they had. And it had a DVI port for my LCD.
I returned home at 2pm (Lawrence Expressway was all carved up for repaving). Oh, I should note that a trip to Fry's and home is 2/3rd of a trip to Yahoo and home. Keep that in mind later.
Before I opened the box, I visited the XFree86 web site and checked the Driver Status to make sure that the ATI Radeon was on the list. If it wasn't, I'd take the card back without breaking the shrink wrap seal and find something that was on the list.
It was on the list! So I opened and installed the card. I connected the VGA cable (since I wasn't sure where the DVI cable for my LCD monitor was) and turned it on.
Same problem.
I spent the next 45-60 minutes trying everything I could think of doing. I moved memory around, reseated the CPU, re-checked connections, etc. Eventually I had the motherboard completely removed from the case and sitting on anti-static bags. I figured that would eliminate the chance of any electrical shorts between the case and the Baird.
Same problem.
I figured the board was fried. But I decided to browse the motherboard installation docs one more time to see if I could find anything I missed. I did.
Apparently, the Pentium 4 CPU is such a fucking pig that P4 boards require a second power connector (12V) on the board. Guess what? The power supply in my 3 year old case doesn't have one of those.
Fuck!
Not only was the case a pain in the ass to work inside (the P4 board was just long enough to get in the way of cabling the drives), the power supply was useless for the new board.
Another visit to Fry's
I haded back out in search of a replacement power supply or a whole new case. After looking at the prices and selection, I opted for a new case--one with more room. I got a case for ~$79 and headed home. I arrived home at roughly 5pm to finish the job.
I removed all the crap from the old case and installed it in the much nicer new case. After everything was plugged in, it worked on the first try.
Success!
Next I proceeded to download the latest Knoppix release (that's what I use on non-servers now), burned a CD and began the process of migrating data off the old hard disks (an 8.4GB and a 20GB disk). It seems that 2003-09-05 had just come out, so I was using very fresh code. Anyway, I figured I might as well put my two spare 80GB disks to use, so I spent the next 1.5 hours moving data around and then installed the drives along with the DVD drive and CD burner.
Video Hassles
Then I booted Knoppix into the GUI mode to poke around and then run the hard disk installer. It came up in 1024x768 mode but I didn't worry. I can tweak the video after the fact. I've managed to make my home "desktop" machine speak 1600x1200 to the LCD using it's built-in less powerful ATI card before.
The install finished and I got everything set the way I wanted, so I set about making the video work right. For whatever reason, Knoppix hadn't figured out that I had an ATI card and was using the vesa driver.
I performed many Google searches and quickly noticed that nasty feeling forming the pit of my stomach. Getting the Radeon 9200 working with XFree86 is not a trivial proposition. At first, this information look promising, except that I'm not running RedHat. But the magic seemed to be telling XFree86 ChipId and using the "ati" or "radeon" driver in the config. (Note: I've always hated X configuration.)
No go. My monitor claims not to be getting a signal when I try that stuff.
More searching.
Found some Debian specific notes. But they require way more effort that I'd like to invest. At 11pm, incredibly pissed off at the PC hardware industry for requiring me to upgrade my power supply and video card, pissed off about having wasted an entire day on this ordeal, I decided to just take the machine to work and get it back on the network. I could always do a bit more searching and muck with the X stuff in the morning.
So I drove to Yahoo and home. Again.
The Next Day
When I got to work today, I experimented with X configs a bit more. All told, I figured I've tried 30-40 different configurations and I'm still using 1024x768 and the vesa driver. I can't get the "ati" or "radeon" drivers to do shit. And I don't even care anymore. I'll use a slow-ass VGA driver if it can drive my monitor at 1600x1200. Hell, I'd settle for 8 bit color at this point. I'm not gaming. Just using xterms and a browser.
So, here I sit with a blazingly fast CPU, lots of disk space, and a beautiful monitor wondering what the hell I should do with it all. Just give up and install Windows? Buy another video card and try to sell this one locally? Throw it all in the dumpster and become a park ranger in Montana?
Seriously, why is this shit so damned difficult?
A Resolution
I resolve to never do this again. From now on, I will "upgrade" by selling my old computer and using the cash to offset the purchase of a brand new, pre-assembled and tested computer. Just like I do with laptops. The only "upgrades" I will ever do myself will involve adding memory or disk space. That's it. Just like I do with laptops.
At this point I really wonder how much time and money I'd have saved by just calling Dell.
Ugh.
There are so many other things I had planned to get done yesterday.
September 05, 2003
I need Comedy Central
One of the downsides of staying in a hotel is that you run the risk of watching a lot of TV. But I've been watching Comedy Central--something I haven't done in years. I never realized how much I missed it!
Not exactly time well spent, but hey.... I'm catching up on some e-mail too. :-)
Anyway... I just thought I'd share that.
Oh, I'm back up in Truckee flying gliders--thus the hotel stay. I did some dual cross-country training today. Had a 3 hour 20 minute flight from Truckee to Spalding (roughly 100nm North) and back to Nervino (roughly 40nm short of Truckee). We could have made it all the way back, but I wasn't feeling so hot. This is a great area to fly in, but it's no fun if you're starting to feel air sick.
More on the flight later, including a GPS trace overlay in the map when I get back home. Tomorrow I go to South Lake Tahoe to fly a DG-1000.
Update: South Park is on next!!! I had totally forgotten about South Park.
Damn, you'd think I was maturing or something. What's with this?
September 03, 2003
Blogging the Home Buying Process?
For a variety of reasons, I recently convinced myself to start shopping for a home and a loan for the home-to-be. I'm wondering if I should blog the process. I wonder if anyone would be interested in the places I look at, the loan offers I get, and what it's like to shop for a house in Silicon Valley (painful, I'm sure).
Or maybe not.
Has anyone done this before? I mean documented it online?
September 02, 2003
Raggle: a console based aggregator
As a fan of console-based tools (mytop, for example) in this "web-based everything" age, I was thrilled to see an announcement for Raggle.
Raggle is a console RSS aggregator, written in Ruby. Features include customizable keybindings, basic HTML rendering, HTTP proxy support, OPML import/export, themes, support for various versions of RSS, Screen support. browser auto-detection, and more. Raggle has been tested under Linux and OpenBSD, and should work properly under other Unix variants as well.
And, as of a few days ago, there's even an optional web front-end to Raggle too.
I need to give it a serious workout. This very cool and has some great hack potential!
September 01, 2003
got books?
A few years ago I realized something strange and was just recently reminded of it (thanks, K). My parents don't really own any books. Neither does my sister (and brother in-law). I guess I was just used to that growing up. But it's odd.
(That's not entirely true, my Dad buys a lot of computer books that he never reads. And my Mom has a small collection of cooking books. But that hardly counts.)
Personally, I have too many books. I have two full-height book cases that are full. I also have 3 half-height cases that are full. And I've vowed not to buy more (cases, not books!). Instead I go thru and get rid of old books that I don't plan to read again. The local library likes that.
Most (but not all) people I know seem to have a decent collection of books too. I know that Amazon.com 1-click isn't completely to blame, 'cause I've always this problem... I'd go to a book store and walk out with at least 4 books. Every time. And when we visited Powell's in Portland during OSCON, I think I walked out with something like 9 books.
And my Amazon Wishlist has 4 pages worth of items on it. There are 88 in total right now. Granted, a few are DVDs, but most are books.
So many books, so little time!
You know, I remember going to my friend Greg's house when I was growing up. They also didn't have [m]any books.
I'm not sure what to make of this.
Is this common? What's your experience?