October 31, 2006
Heading to UIUC for a University Hack Day...
![]() This morning I'll hop on a flight eastward into the Midwest so I can spend a couple days out at UIUC as part of our University Hack Day program. I'm looking forward to seeing a sampling of college generation hacks.
This morning I'll hop on a flight eastward into the Midwest so I can spend a couple days out at UIUC as part of our University Hack Day program. I'm looking forward to seeing a sampling of college generation hacks.
Wow. I guess it's been about 10 years since I was an undergraduate in Computer Science. Yikes! How the time flies...
It looks like the daily high temperatures there are supposed to be near the daily lows here, so I'm in for my first real dose of cold.
October 30, 2006
Aerial Self Photography
Anyone who watches my Flickr photostream knows that I like to take aerial shots when flying gliders. Having a camera you can stick out the window means there are a lot of cool shots you can get--eventually. There's a lot trial and error involved.
Usually I'm trying to get just the right mix of horizon, glider canopy, and ground in the shot. But yesterday it occurred to me that I never really tried taking pictures of myself.
My first attempt came out far better than I expected.

I rather like it!
Of course, this was made easier by the fact that Mike was in the front seat flying. :-)
I'm hoping to get a little camera mount I can try from a few other vantage points within the glider. More on that later.
To see the other shots I took, check out this photoset.
October 29, 2006
Is HD Radio Worth It?
Being a non-hip kind of guy, I don't fill my commute with podcasts that you've never heard of. Instead, I listen to old-school FM Radio. Even at home, I find myself listening to the radio about half the time. That's despite the fact that I have a music collection in the range of 500 CDs, all of which exist as MP3s on my computer. But there's something to be said for the simplicity of "push the button and the music starts--no crashes, boot up time, or software updates." Luckily my iPod Nano is pretty reliable too.
I listen primarily to three radio stations. Roughly classified, they are:
- Classic Rock (on 98.5 KFOX)
- Public Radio / NPR (on KQED)
- 80s, 90s, etc. (on 95.7 Max FM)
I listen to the first two in roughly equivalent doses, while 95.7 is more of a "filler" station. Sometimes they play a lot of stuff I like, other times I can't stand it.
KFOX has been pushing HD Radio pretty hard. That got me wondering if it's worth even thinking about. I have no trouble with reception and find the broadcast sound quality to be just fine for my tastes. Reading about HD Radio on Amazon.com doesn't help much either.
The digital technology even enhances the AM and FM bands' audio fidelity--AM sounds more like FM does today, while FM signals boast a CD-like quality. Best of all, the static, hiss, pops, and fades commonly found on today's radios are virtually eliminated, ensuring crystal-clear reception.
I can't remember the last time I noticed static, hiss, pops, or fades. In other words, they've been "virtually eliminated" without me having to do anything.
The way I see it, most HD Radios seem to pretty expensive ($150+) and I'm not seeing much of a benefit. Therefore, I ask you (my technically minded often leading edge readers): Am I missing something? Is HD Radio really worth going after? Or should I just wait until HD is standard and costs 20% of what it does today?
See Also:
- Getting More Stations For Your Car Radio (Fred Wilson)
October 26, 2006
Donna Bogatin tries to be funny. Gets basic facts wrong.
Over on ZDNet, Donna Bogatin tried to be funny today. But she ended up getting basic facts wrong in her attempt to mock me (and/or Yahoo).
I don't run AdWords
This is a little hard to believe for someone writing at ZDNet, but she managed to accuse me of running AdWords. Except that I'm not. I'm using AdSense, the Google advertising system that random people can sign up for to stick ads on their web site. AdWords is where you pay Google to advertise. They're really two very different things.
To put this in plain English: AdSense is for publishers. AdWords is for advertisers.
I don't need YSM
Continuing her confusion about advertisers and publishers, she says:
But does Zawodny know HE can always advertise through Yahoo? Yahoo Search Marketing isn't that hard to find, is it?
Huh? Yahoo! Search Marketing (YSM) is our rough equivalent to AdWords. It's where people go to bid on keywords and submit their ads. I have nothing to advertise, so this is a bizarre accusation.
Perhaps she's thinking of the Yahoo! Publisher Network (YPN), our AdSense competitor that's in limited beta?
Yeah, I've tested that. I even mentioned that over a year ago. And, if you're curious, I'll likely have another test running soon.
Conclusion
I guess the lesson is that someone who writes about "digital micro-markets" can't tell the difference between products aimed at publishers and those aimed at advertisers. I guess the further lesson is that such a person, in their rush to publish, doesnt examine my previous public statements on the matter (using this magic "search" technology).
Donna, you're not making ZDNet look very good. Please stop. You can do better than this (I hope).
You're welcome to google on Yahoo
In reacting to Google's Do you "Google?" post, I think Ben Metcalfe speaks for a lot of people. In Google can go shove their lexicographical advice up their ass he says:
But in the end, regardless of whether its positive, harmful or somewhat in between for Google, I for one dont like to be told how to use the English language.
The decision of which words I use is my decision. The decision to refer to trademarked terms as generic terms in conversation through to casual blogging is my decision. Together as society, the choice of which terms are used regularly and thus become officially public domain is our decision.
We own our language. So Google, you can go shove your lexicographical advice up your ass.
I think it's been well established that fighting the will of your users is a bad idea (see also: Friendster). So, as far as I'm concerned, you're more than welcome to google on Yahoo. Or MSN. Or Ask.com.
In fact, why not google wherever the hell you want. Search boxes really aren't that hard to find nowadays, are they?
But the if the lawyers really do threaten you, I guess you could always yahoo.
Heh.
Update: Apparently John is equally impressed.
Update #2: If you've ever wondered when you can Ask or ask, the folks at Ask are glad you asked. This is just comical now! :-)
October 24, 2006
Find Cheap Smog Checks Quickly On-Line
One of the joys of living in California as opposed to, say, Ohio is the ritual of getting a smog check for your vehicle every couple of years. There are tons of places (often gas stations) with "smog test" or "smog check" signs out front, but where can you go for a deal?
![]()
eSmogCheck is the answer. Simply give it your zip code and it shows nearby smog check stations and their prices. Some establishments have joined the Internet revolution to offer on-line reservations and special pricing.
I just finished doing this year's round of smog checks, but next time around I'm gonna use eSmogCheck. It looks like I could have saved some cash.
October 23, 2006
All My Free Time Are Belong to Ruby on Rails
It has begun. Armed with last week's worth of reading (this, that, and so on) about Ruby and Ruby on Rails, and watching screencasts, I've crossed that magical boundary and typed these fateful commands a little while ago:
gem install rails --include-dependencies rails chapter-1 cd chapter-1 script/server script/generate controller Greeting vi app/controller/greeting_controller.rb script/generate controller Greeting index vi app/views/greeting/index.rhtml
Where this heads is anyone's guess, but I'm truly amazed at how much of the lifting I don't even have to think about.
Aborted Crosswind Landing Video
After watching this video, I'll never be ashamed to do a "go around" on a questionable croswind landing appraoch.
Heh.
I'm sick of Sharing
More precisely, I'm sick of being told to "share" every damned piece of "content" I run across on the Web.
It seems to me that "share" has been abused into such a generic term, that I have no idea what's going to happen when I click on of those "share" links. The things I've seen to date are:
- pop-up that pisses me off
- a login page appears (WTF?!)
- new page loads (in a tab), resizes firefox, and pisses me off (*cough* YouTube *cough*)
- an in-line form appears
- my email client pops up
- I'm taken to a page that with a To:, Subject:, and Body fields along with instructions for posting on my blog
- I'm taken to a page that explains how to embed a Flash widget on MySpace
I'm sure there are other "sharing" behaviors I've yet to encounter. Some probably involve various IM clients. And SMS. And carrier pigeons.
Why is it that almost nobody can think of a way to represent "email this to a friend" without using the word "share"? I seem to run into "share" links all over the freaking place. Sometimes the single word "share" is the link. Thats' really descriptive, guys. Good design.
And they seem to be placed on the sites under the assumption that I'm too stupid to send email (to the people I presumably email frequently already) with a URL in it (see above list). Thanks for the confidence boost.
WTF?
I guess an honest link title would be too verbose, huh?
If you're like most of our users and can't figure out how to email the URL of this page to your similarly clueless friends, fear not! Click here. We really want to make it easy for your friends to come to our site and click on ads.
Can we please come up with a better euphemism? All this spamming (err, I mean "sharing") is getting on my nerves. Thankfully, few of my friends have taken to this "sharing" craze with any real fervor. I guess that's one way to tell your real friends from those who just want to be friends in a "Web 2.0 social networking" sort of way, huh? :-)
For my taste, I prefer the far more direct "Email Story" link that's on the bottom of most Yahoo! News story pages. At least the intent is clear before I click.
Email isn't exactly new technology. So part of me wonders why nobody's trying to teach people to fish rather than giving them fish. Is the whole "copy URL, paste URL, send message" exercise really that hard?
Oh, right. There's no profit in that!
By having a separate page that I can use to spam my friends, sites get to increase their available advertising "inventory" by a small but maybe measurable percentage.
Yay!
[Before you accuse me of over-estimating how "easy" it is to copy and paste, consider this: None of those email forms have any knowledge of my address book anyway. So I've gotta either remember and correctly type a bunch of my friends' email addresses in order to use them--or I have to, you guessed it, copy and paste them from my address book. Back to square one, huh?]
October 20, 2006
Programming Humor at The Daily WTF
If you're a programmer or otherwise involved in creating software, you should really be reading The Daily WTF. Where else will you see gems like this?
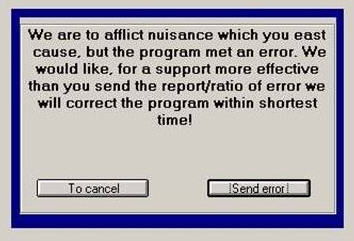
There's a good selection of seriously messed up development stories there too. The recently posted Very Slow Service is one of my favorites. It's a great little database optimization story with a very predictable and political outcome.
October 19, 2006
Some Soaring Videos and Stories
Since the soaring season has nearly come to a close for much of the country, I present some soaring videos, stories, and sites worth spending some time with while you're stuck on the ground.
Kempton's Adventures
Kempton Izuno, a long time pilot flying in California and the Great Basin, has been documenting his adventures for some time now. They're great reading for aspiring XC pilots:
- 1995 Tonopah Adventures: early adventures flying out of Tonopah, Nevada including a great landout and retrieve story
- 1000k Days at Tonopah (1998): Kempton and friendswent back to Tonopah in 1998 in his standard Libelle, aiming for at least one 1000km flight.
- My First Big Cross Country Flight: from 1977, flying out of Truckee in a 1-26.
- Sierra Distance Flying (1992, part 1): the story of how Kempton won the Hilton Cup in his Standard Libelle flying Truckee and Minden
- A Standard Libelle Wins the Hilton Cup (1993): this is part 2 of the previous story, a great narrative of his winning flight
Mountain Wave Education
I was recently pointed at an excellent web site for learning about Mountain Waves and Downslope Winds that's part of a larger Mesoscale Meteorology Primer.
I've on looked at this briefly, but it definitely seems worth reading.
Morning Glory
A cloud known as 'Morning Glory' forms in the remote Australian outback of northern Queensland which offers some of the most dramatic and exciting gliding conditions in the world. You can read about it thanks to the cloud appreciation society or watch a video thanks to Google Video.
Bruce's Phoebus and ASW-20 Videos
While doing some searches on Yahoo! Video for soaring clips, I came across one of Bruce's videos. He owns a Phoebus and an ASW-20. He's taken some video flying in Utah.
Good stuff.
October 18, 2006
YouTube and Google: Im Glad Somebody Finally Said It
You may have noticed that I never wrote anything about Googles recent acquisition of YouTube while the rest of the world seemed to be.
Thats not entirely true. I wrote about it a bit on an internal mailing list at work. What I read there and all over the Internet shocked me. A significant proportion of people completely missed the point. They thought Google had gone off the deep end.
I was shocked. It was so pervasive that I figured I better keep quiet, since I was obviously missing something.
People wrote about how the site is ugly, the technology sucks, the potential legal problems, and so on. They made passionate arguments that sounded convincing if you didnt understand the business that Google is in.
The Light
My hats off to Dave McClure, the Master of 500 Hats for finally saying it.
Its not about community, design, technology, or copyright. Its about eyeballs. Lots and lots of eyeballs. Its 1999 all over again.
Google bought themselves a really, really big video advertising distribution network (or platform if you prefer).
Can someone please explain to me why this wasnt blindingly obvious to a lot more people? Im at a loss here. I have been since the speculation of the deal first surfaced.
Another Way
In trying to explain this to people, I pose a different question: What's the single biggest threat to Google's continued growth?
The variety of answers I get is interesting, but few people hit the one I have in mind: a lack of inventory. Their ability to find new places to stick ads is the single biggest threat to the continued growth for their business.
That's why they're doing deals with MySpace, Dell, and all sorts of companies. It's all about the eyeballs, or inventory (as DanR recently said[*]).
I don't know about you, but as a Google shareholder, I'd be pretty upset if they weren't pursuing deals to expand their inventory. Of course, as a Yahoo! shareholder and employee, I hope they're not too successful. :-)
* Note to Thomas Hawk: That was kind of a cheap shot, with you being the Chief Evangelist for Zoomr, a Flickr competitor--one whose name makes me think "copy cat."
October 16, 2006
Why APIs?
Given that I helped start the Yahoo! Developer Network and once again spend my days (and some nights) working on it, you should not be shocked to know that I think APIs are pretty important.
This all goes back to something I tried to articulate a couple years ago (around the time we were working on making the Search APIs available, IIRC): Ubiquity in the Internet Age. In that post I made two claims about the web that I'd like to make once again:
- The web enables infinite distribution of content without any special effort or infrastructure.
- The web extends the reach of our apps and services as far as we're willing to let them go.
I went on to say:
The closer to everywhere you can reach, the better off you'll be.
Where is everywhere?
The notion of everywhere has changed too. It's not just about every desktop anymore. It's about every Internet-enabled device: cell phone, desktop, laptop, tablet, palmtop, PDA, Tivo, set-top box, game console, and so on.
Everywhere also includes being on web sites you've never seen and in media that you may not yet understand.
That eventually led into a discussion on APIs and Syndication (RSS/Atom) that began with:
Giving users the ability to access your data and services on their own terms makes ubiquity possible. There are so many devices and platforms that it's really challenging to do a great job of supporting them all. There are so many web sites on which you have no presence today. By opening up your content and APIs, anyone with the right skills and tools can extend your reach.
But until that point, this was largely based on evidence I'd seen elsewhere: Flickr, Amazon.com, and so on. So we'd been doing some of it on the "if you build it, they will come" faith along with a dose of common sense and reason.
But that was all two years ago, so I'd largely forgotten that I wrote most of that (just like most of you, I suspect).
It all came back in a flash last week when someone pointed me at Kevin's Yahoo Answers on Mobile. It's a textbook case (if there is such a thing) of someone being able to put one of our services on their device:
...For me that geek speak which is foreign to me is soccer. I played football my whole life and the rules and lingo in soccer leave me baffled. When folks are talking about soccer, I feel like a shmoe and sort of drift off. I wish I knew more about the game.
There is clearly a problem here looking for a solution. I have my cell phone with me and would love to be able look up some of the soccer terms on the fly, get answers, and get involved in that conversation.
To that end, on the way to Emmas first game we stopped at Barnes and Noble. I picked up a cup of coffee and an issue of Business 2.0. One of the articles was about Yahoo Answers. Yahoo Answers had 12 million uniques in June (YouTube had 13 million). This is clearly a hot and valuable web property and for a reason. It is a great resource for learning things in a hurry.
I could instantly become a soccer expert with Yahoo Answers on my cell phone.
And he did just that.

Back that "Why APIs?" question... So that Kevin can become a soccer expert at his kindergarten daughter's games.
That's why.
When Help Doesn't Help
As is often the case, an email message in my inbox had a calendar appointment attached to it. I dutifully clicked the attachment so that Outlook (which I use only for calendaring purposes) would ingest it. This time, however, it refused to do so.
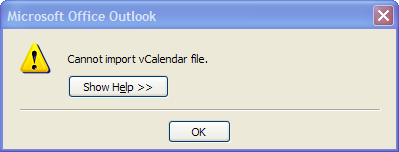
Clearly in need of help, I clicked the "Show Help" button.
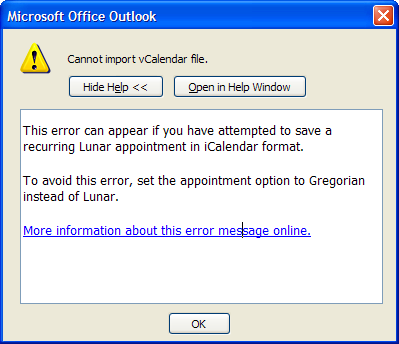
As you might have surmised, that doesn't help at all. I don't know how to "set the appointment option" either in general or in this specific case. Clearly in need of more help, I clicked the hyperlink "More information about this error message online" and hoped to get more information.
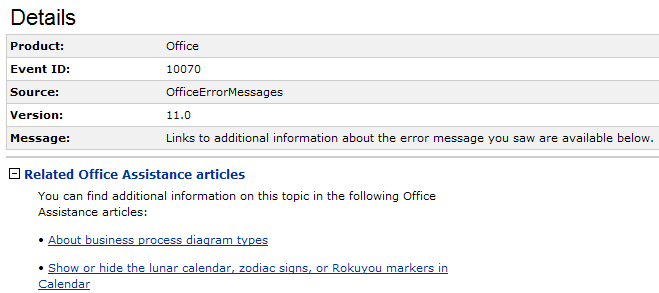
Strictly speaking, I guess I got "more" information--mainly some useless metadata about the error.
Is it any wonder that I don't entrust my actual email to Outlook too?
October 14, 2006
A Visit to the Hiller Aviation Museum in San Carlos
I've probably driven by the Hiller Aviation Museum in San Carlos 50 times in the last 6-7 years. It's visible from the 101 but I never managed to get myself up there until today.

The museum contains a good collection of older aircraft, engines, propellers, and other static displays in a relatively small space. In fact, I was a bit surprised at how much they were able to pack in the place.

While there are many displays that caught my attention for one reason or another, the partial 747 outside was just damned cool. Where else can you climb into the cockpit of a 747 and look around?

Amusingly, the emergency exit doors still work. You're not supposed to open them, but that's not obvious until you've already done so (assuming you're outside the aircraft).

Heh. Oh, well. No alarms went off. :-)

More pictures are available in my Hiller Aviation Museum set on Flickr.
See Also:
October 10, 2006
Following Scott Adams' Financial Advice?
It seems that Paul Farrell at MarketWatch thinks that Scott Adams' 9 point financial plan is worthy of a Nobel Price in Economics. Scott (yes, the Dilbert guy) sees this as another example of being in over his head.
Whatever.
Let's look at Scott's plan. It's actually not a bad personal finance benchmark:
- Make a will
Nope. I haven't done that yet. - Pay off your credit cards
Done. - Get term life insurance if you have a family to support
No family to support, so no life insurance. - Fund your 401k to the maximum
Done. Thank you, Vanguard! - Fund your IRA to the maximum
Done. Thank you, Schwab! - Buy a house if you want to live in a house and can afford it
Done. It's not even close to paid off, but I'm chipping away at it. - Put six months worth of expenses in a money-market account
Done. - Take whatever money is left over and invest 70% in a stock index fund and 30% in a bond fund through any discount broker and never touch it until retirement
Sort of. I have more like 95% in stocks right now, but I'm also nowhere near retirement yet. - If any of this confuses you, or you have something special going on (retirement, college planning, tax issues), hire a fee-based financial planner, not one who charges a percentage of your portfolio
I'm not confused, retiring, planning for college, or having tax issues.
Overall, I guess I benchmark pretty well. How do you do?
October 09, 2006
Hit Counter 2.0, or "Web 2.0 Metrics"
![]() Way back in the early days of the Web (you know, before AdSense, blog spam, web mail, and dynamic HTML) were these things called hit counters. The Wikipedia article says a few things that I'll just quote outright.
Way back in the early days of the Web (you know, before AdSense, blog spam, web mail, and dynamic HTML) were these things called hit counters. The Wikipedia article says a few things that I'll just quote outright.
On Popularity:
At one time it was common to see a hit counter on every page, but this is no longer the case for several reasons:
- They have been replaced (or augmented) by more complicated web analytics methodologies that give the webmaster a better overall picture of site traffic besides a simple, perpetually increasing number.
- As style elements, they are no longer associated with the impression of professional web design--some people consider web counters to be a "gimmicky" feature and they are thus typically found on personal pages created by individuals.
- The number of visitors to a site may be a trade secret
- Too small a number might indicate the page's lack of popularity. Removing the counter thus levels the playing field.
On Trust:
Web counters are not necessarily trustworthy. A webmaster could start the counter at a high number to give the impression that the site is more popular than it actually is.
Heh. You think?
Web 2.0 Metrics
I present this little walk down memory lane because it's related to something I've been wondering about. How the hell do we count stuff in a zero page refresh Web 2.0 buzzword compliant world?
Evan Williams recently declared Pageviews are Obsolete. Among his reasons are Ajax and RSS.
But Ajax is only part of the reason pageviews are obsolete. Another one is RSS. About half the readers of this blog do so via RSS. I can know how many subscribers I have to my feed, thanks to Feedburner. And I can know how many times my feed is downloaded, if I wanted to dig into my server logs. But I don't get to count pageviews for every view in Google Reader or Bloglines or LiveJournal or anywhere else I'm syndicated.
Ah, a sticky problem. One that should demand the attention of metrics companies like comScore and Nielsen NetRatings.
Over at Techdirt, they're asking Where Are The Web 2.0 Audits?
Want to start a business that is desperately needed? Get into the Web 2.0 auditing business (or perhaps that's Auditing 2.0). Just as with the last bubble, it's reached the point that you can't trust any of the numbers that are being floated concerning today's popular sites. Of course, we've covered repeatedly how questionable the valuations being tossed around are, but to support those bogus numbers, it seems that there are all sorts of other bogus numbers being thrown around as well.
Want an "old company" example of where this could get interesting? Yahoo! Mail. It has certainly accounted for billions and billions of "pageviews" over the years. But the fancy new version that's been rolling out is a lot more like a desktop mail reader than what most users are used to.
What's the right way to count the activity that Wall Street and advertisers care about?
- messages viewed
- ads requested
- active users
- time on site
- clicks
What subset of the possible metrics is both meaningful and not specific to a web mail application? That is, which metrics are broadly applicable to sites that employ similar technology for very different activities?
What about comparing sites that compete for users (and advertising dollars) but use radically different presentation technologies?
Beats me. But if you're starting to think this might be a little complicated, I'll leave you with a final quote from Ev's article:
In summary, there's no easy solution. There's a big opportunity (though very tough job) for someone to come up with a meaningful metric that weighs a bunch of factors. But no matter what, there will come a time when no one who wants to be taken seriously will talk about their web traffic in terms of "pageviews" any more than one would brag about their "hits" today.
Thoughts?
From My Inbox
I think these pretty much speak for themselves...
First off, we have one of the dumbest bits of SEO spam I've seen in a long time:
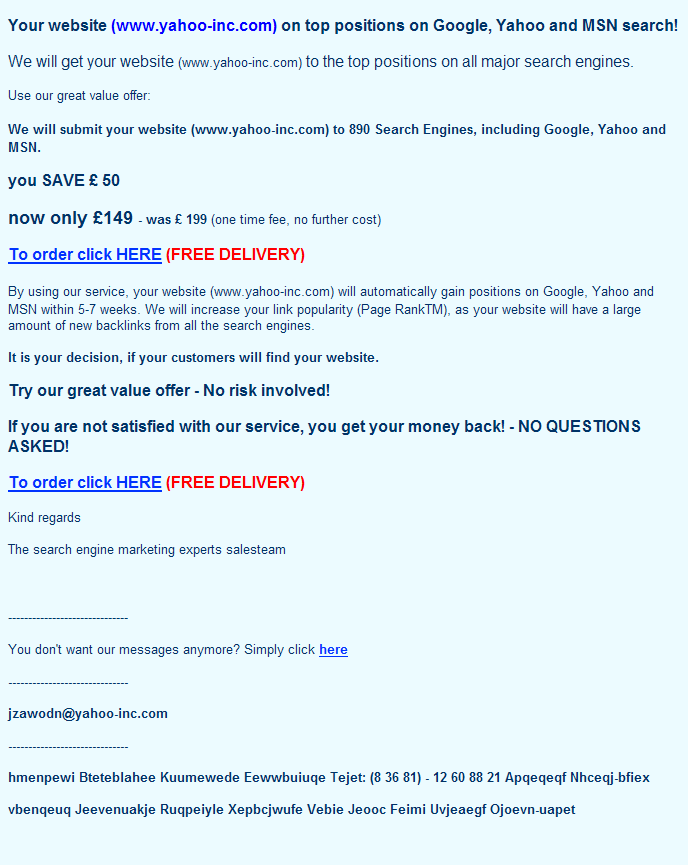
(For those who don't "get it", realize that www.yahoo-inc.com 404s.)
And then one of the weirdest attempts at a blog comment.
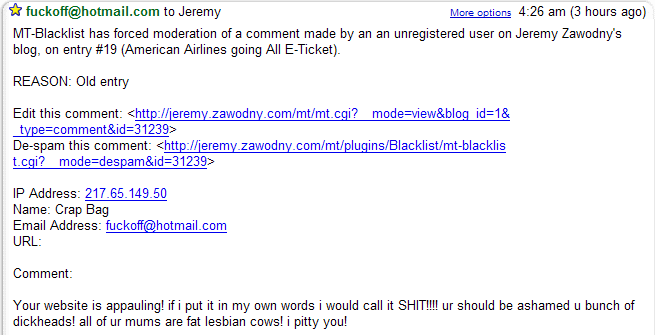
Both of these make me question the long-term prospects for the human race. But maybe I've just got a case of the Mondays.
October 06, 2006
A List of Amazon S3 Backup Tools
In an effort to replace my home backup server with Amazon's S3, I've been collecting a list of Amazon S3 compatible backup tools to look at. Here's what I've discovered, followed by my requirements.
The List
I've evaluated exactly zero of these so far. That's next.
- s3sync.rb is written in Ruby as a sort of rsync clone to replace the perl script s3sync which is now abandonware. Given that I already use rsync for much of my backup system, this is highly appealing.
- Backup Manager appears to now have S3 support as of version 0.7.3. It's a command-line tool for Linux (and likely other Unix-like systems).
- s3DAV isn't exactly a backup tool. It's provides a WebDAV front-end (or "virtual filesystem") to S3 storage, so you could use many other backup tools with S3. Recent versions of Windows and Mac OS have WebDAV support built-in. Java is required for s3DAV.
- S3 Backup is an Open Source tool for backing up to S3. It's currently available only for Windows. Mac and Linux versions appear to be planned. The UI is built on wxWidgets.
- duplicity is a free Unix tool that uses S3 and the librsync library. It is written in Python but not considered suitable for backing up important data quite yet.
- S3 Solutions is a list of other S3 related tools on the Amazon Developer Connection.
- Brackup is a backup tool written by Brad Fitzpatrick (of LiveJournal, SixApart, memcached, perlbal, etc...). It's written in Perl, fairly new, and doesn't have a lot in the way of documentation yet.
- Jungle Disk provides clients for Mac, Windows, and Linux. It also offers a local WebDAV server.
- DragonDisk has Linux and Windows clients.
For those keeping track, non-S3 options suggested in the comment on my previous post are Carbonite, rsync.net, and a DreamHost account.
Are there other S3 tools that I'm missing?
Also, I've found that Amazon's S3 forum is quite helpful. The discussion there is generally of good quality and the software does the job nicely. Perhaps we should do something similar for YDN instead of using Yahoo! Groups?
My Requirements
Most of what I need to backup lives on Linux servers in a few collocation facilities around the country (Bowling Green, Ohio; San Jose, California; San Francisco, CA). My laptop and desktop windows boxes have USB backup and get automatically synced to a Unix box on a regular basis already using the excellent SyncBack SE, so I don't need to re-solve that problem.
I don't really need a fancy GUI. I'm really looking for a stand alone tool that's designed to work with S3 and keep bandwidth usage to a minimum. Alternatively, something that works at a lower level (such as a filesystem driver) to provide a "virtual drive" type of interface might work as well.
October 04, 2006
This just made my morning...

Thanks to Danny Sullivan for crafting that one and pointing at Custom Google.
The site claims to offer a custom Yahoo feature too, but the domain it sends you to is full of ads (is that some sort of statement about the Yahoo home page?).
For whatever reason I'm really tired this morning eventhough I felt great when I woke up. This little image amused me though.
Now back to plowing through all the email I'm behind on. Again.
October 03, 2006
Replacing my home backup server with Amazon's S3
Not too long ago, Amazon released their Simple Storage Service (or "S3" for short). It provides a hosted storage platform which developers can build all sorts of applications on top of. Smugmug, a popular photo sharing web site, is using it to store and host pictures.
I've been considering using S3 as the backend to an on-line backup, since I'd been beating that for a while (see: Swimming Pools and Hard Disks and Cheap On-Line Storage Coming Soon).
In a few days I'll write about how to do this--I'm only partially through the process right now. But right now I want to lay out the motivation for doing this.
The Cost of A Home Server
Amazon's pricing model is pretty compelling. The current rate is that I'd pay $0.15/GB monthly for the data I store. Data transfer costs $0.20/GB.
My home server is a 2.4GHz Pentium 4 that contains 3 250GB SATA disks in a RAID configuration, plus an 80GB boot and OS disk. I decided to measure its power use using my Kill A Watt and found that it consumes roughly 120 watts of power with the CPU idle and disks spinning. That's about 80 kilowatt hours every four weeks. According to PG&E's Residential Rates, the average cost of electric power in San Jose is $0.16247 per kilowatt hour.
My home server costs me a minimum of $13 every four weeks just to leave powered on and idling, or $170 per year. That doesn't count the roughly $700 I sunk into the disks and the other $700 I likely spent on the motherboard, CPU, case, RAM, and so on. Remember, these are absolute minimums, since the CPU does consume more power when it's actually doing work.
So if we assume that I spent $1,400 on the server and would keep it for 5 years, that's another $22 per month (4 weeks) of costs.
If you're keeping score, that's $22 + $13 = $35 every four weeks just to have backups of my stuff (most of which lives on servers in a few datacenters).
That puts the total cost for 5 years worth of backups around $2,275 assuming that no hardware breaks.
The Cost on S3
My backups require about 125GB of disk space today without compression. That'd cost me $18.75 per month to store on Amazon's S3. Let's further assume that I increase that by 1GB/month for the next five years (mostly photos) and transfer about 2GB every week doing backups (log files, mail, and other temporary stuff is much of that).
2GB every week is 8GB every four weeks, which costs another $1.60 every four week "month" for a total of $20.80 per year or $104 over 5 years.
Assuming that growth rate has me up to 190GB five years from now. Let's call it 200GB. If I'm growing at a constant rate, I can use the average of 200GB and 125GB, which is 162.5GB. Multiply that by 13 "weeks" and 5 years yields $1,584.
Adding it all up, if those guesses are right and we assume that Amazon's prices don't fall (they certainly could in a few years), I'd end up paying $1,688.
In other words, switching to S3 could save me $587 over five years!
Other Benefits
It's clear that going with S3 could save me money both from a reduced electric bill and not having to buy backup hardware (server and disks). But why else might I do this?
- Availability. It's less likely that Amazon's service will go down when compared to my home server and residential grade broadband service.
- Speed. If a remote server dies, I'd need to push all the bits there from my artificially slow DSL or Cable connection at home. Using S3 means I can restore faster.
- Simplicity. This is one less Unix box I have to spend any time administering. Even if it's only 5 minutes every week or two, that all adds up.
Again, I'll write up the process (tools and stuff) in a few days (or weeks).
Update: The economics are even better than I thought. It turns out that I mis-read some du output last night. I really only need half the space I thought I did. That is, ~75GB today instead of 125GB. Hmm...