February 29, 2008
Chicken Tortilla Soup Crock Pot Recipe
 If you have a slow cooker (or "crock pot") and enjoy tortilla soup, here's a good recipe to try out.
If you have a slow cooker (or "crock pot") and enjoy tortilla soup, here's a good recipe to try out.
Ingredients:
4 chicken breast halves
2 14.5 oz. cans of chicken broth
1 garlic clove, minced
2 tbsp. margarine
2 12 1/2 oz. cans of chopped stewed tomatoes
3 cups hot salsa
1/2 cup chopped cilantro
1 tbsp. or so of ground cumin
tortilla chips
Optional:
cheese (whatever you prefer in your soup)
sour cream
The steps:
- Grill the chicken breasts. Shred them with a fork and knife.
- Combine all ingredients except cheese, sour cream, and chips.
- Cover the pot and cook on low for 8 to 10 hours.
- Enjoy the soup, adding chips, sour cream, and cheese to taste.
What I like about this recipe is that it's incredibly simple, involved grilling (always fun), and takes no more than about 15 minutes to get going. You're then left with enough soup for four adults (or two for two days in our case).
Personally, I skip the cheese and sour cream. The soup itself is excellent with some chips added in.
February 28, 2008
How to Copy a Filesystem and Preserve Hard Links in Linux
As part of my Linux backup scheme (which I need to write up someday) I've recently been swapping and upgrading/replacing some USB hard disks at home. There's a Linux box at home (a Thinkpad T43p running Ubuntu if you must know) that has a 320GB disk attached and mounted as /mnt/backup and was running fairly low on space.
jzawodn@wasp:/mnt$ df -h /mnt/backup Filesystem Size Used Avail Use% Mounted on /dev/sdb1 276G 211G 51G 81% /mnt/backup
That was after I moved about 50GB of stuff off it last night.
I want to replace it with a newly attached 750GB disk and need to move all the data over to the new disk. But since much of the data consists of remote filesystem snapshots produced using rsnapshot, which makes copious use of hard links, it's rather important that I do this correctly. If I don't, the data won't even fit on the 750GB disk!
(If that seems impossible, you don't quite grok hard links on a filesystem yet.)
Digging deep into my Unix past, I remember needing to do this once before. The trick was not to use any of the usual suspects: cp, tar, rsync, or mv. Instead, you use either dump (yuck) or a combination of find and cpio.
It looks something like this:
mkdir /mnt/backup2/snaps cd /mnt/backup/snaps find . -print | cpio -Bpdumv /mnt/backup2/snaps
Then you just wait a long time while stuff scrolls by and you wish you were using disks in eSATA enclosures rather than in USB 2.0 enclosures.
The trouble is that cpio didn't properly preserve timestamps on directories (not sure why--I expected it to), so I had to dig even deeper to remember pairing up dump and restore.
cd /mnt/backup2 mkdir snaps ( dump -0 -f - /mnt/backup/snaps | restore -v -x -y -f - ) >& ~jzawodn/dump.log
And then I waited about half a day for the copy to complete.
root@wasp:~# df -h Filesystem Size Used Avail Use% Mounted on /dev/sdb1 276G 212G 50G 82% /mnt/backup /dev/sdc1 688G 284G 370G 44% /mnt/backup2
Not bad. A quick edit to /etc/rsnapshot.conf to change my snapshot_root from /mnt/backup to /mnt/backup2 and that's all it took.
Next time I have to go through this, it won't take me nearly as long to devise a scheme to get it done.
Now, does anyone have alternative methods? Or do you know why cpio didn't preserve timestamps correctly?
Thanks to the folks at TechCzar for translating my tech blog posts and including them in their blog network.
February 26, 2008
FriendFeed Launches, Provides New Lightweight Social Activity. Needs API.
When I thought about writing this last night, I didn't realize that FriendFeed was launching. Good timing.
My intent was to point out two things, really. First off, usage of FriendFeed seemed to be really picking up steam in the last few weeks. In retrospect, that's probably because they were letting more and more folks into the private beta as they got closer to launching.
But the more interesting thing to me was the fact that my FriendFeed activity stream has become a new place for folks to comment on things I'ma doing and even voice their approval. For example, my blog post titled The Difference Between the Rich & Famous and the Rest of Us got a few reactions yesterday.
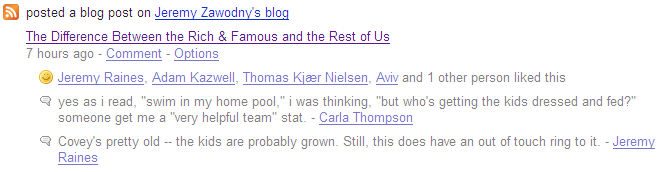
That made me wish there was a FriendFeed API so that I could surface that discussion back on my blog. So I made a comment on Twitter and that garnered even more discussion on my FriendFeed.
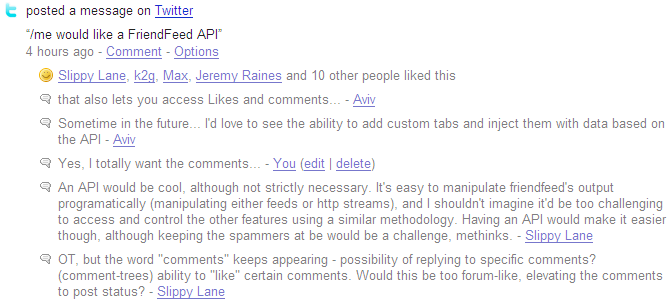
This is all pretty interesting. FriendFeed is, in a way, attempting to join together the loosely coupled bits of social "exhaust" I produce on the web. And at the same time, they've created another new source of activity that I'd like to pull back onto my own web site.
Once the FriendFeed API is out, a whole bunch of interesting stuff is bound to happen. Watch this space.
See Also: Friendfeed, the best software for conversations, raises round and launches publicly on VentureBeat
February 25, 2008
The Difference Between the Rich & Famous and the Rest of Us
Occasionally the Zen Habits blog publishes something I find particularly interesting--usually because the author has figured out way to explain something that's more simple and more clear than I do. And I'm a big fan of simplicity and clarity.
But today's interview with Stephen Covey is not only useless, it's a slap-in-the-face reminder of how different the lives of the Rich and Famous are from the rest of us.
Allow me to quote two of his answers.
On his "morning routine" he says:
I make an effort every morning to win what I call the private victory. I work out on a stationary bike while I am studying the scriptures for at least 30 minutes. Then I swim in a home pool vigorously for 15 minutes, then I do yoga in a shallow part of the pool for 15 minutes. Then I go into my library and pray with a listening spirit, listening primarily to my conscience while I visualize the rest of my entire day, including important professional activities and key relationships with my loved ones, working associates and clients. I see myself living by correct principles and accomplishing worthy purposes.
Okay. What about the "normal" stuff that the rest of us do? Making breakfast, feeding cats, putting away laundry, going to work, and so on?
His next answer, about removing "distractions", sheds a bit of light on that one:
I am fortunate to have a very helpful team that enables me to spend time doing things that are important but not necessarily urgent. This requires the development of a personal mission statement to give a larger context and also the determination of what is truly important but not necessarily urgent. People who have no such team need to also make these larger decisions so that they can cheerfully say No to that which is urgent but not important. Learn to use technology in such a way as to filter out that which you really know is important to you personally and professionally. Remember, technology is a great servant, but a terrible master.
Ah ha!
So what you really need is a "very helpful team" (is that the term for undocumented domestic help these days?) so that you can spend more time on the "development of a personal mission statement" to, you know "give larger context" and all that.
Now it all makes sense!
This is practical and down-to-earth advice that I can use to improve my life right away!
</sarcasm>
February 20, 2008
Hadoop Reactions & Announcement of Hadoop Summit at Yahoo!
![]() I have to say, I'm impressed at the coverage that news about our production Hadoop deployment in Yahoo! Search got yesterday (and today). Here's a quick list of the stories.
I have to say, I'm impressed at the coverage that news about our production Hadoop deployment in Yahoo! Search got yesterday (and today). Here's a quick list of the stories.
- Yahoo! Launches World's Largest Hadoop Production Application by Eric Baldeschwieler
- Yahoo! Search running Apache Hadoop on Large Scale by me
- Open source grid computing takes off by Matt McAlister
- Yahoo Search Wants to Be More Like Google, Embraces Hadoop on TechCrunch, complete with an Apples to Oranges comparison
- Yahoo Search Index Now Supported By Open-Source Hadoop Architecture on Search Engine Land
- Yahoo Gives Hadoop A Big Hug on WebProNews
- Meanwhile, Hadoop News by John Battelle
- Hadoop Now at the Heart of Every Yahoo! Search on the Yahoo! Search blog
- Do You Have an Internet Sized Problem? on More News
- Yahoo + Hadoop on 10k Cores on Kevin Burton's FeedBlog
- Yahoo Embraces Open Source Some More with Hadoop Inside Search Webmap on Search Engine Journal
I guess good technology makes for good news, huh?
Also, today we're opening up the invite list for the Hadoop Summit to be held on March 25th at Yahoo! in Sunnyvale, California. For more on that, check out:
- Announcing the Hadoop Summit at Yahoo, March 25th, 2008 on the Yahoo! Developer Network Hadoop blog
- Hadoop Summit the event page on the Yahoo! Developer Network
- Hadoop Summit on Upcoming.org
As I've said before, this is gonna be quite a heard for Hadoop. :-)
February 19, 2008
Yahoo! Search running Apache Hadoop on Large Scale
Over on the Yahoo! Hadoop blog, you can read about how the webmap team in Yahoo! Search is using the Apache Hadoop distributed computing framework. They're using over 10,000 CPU cores to build the map and processing a ton of data to do so. They end up using over 5 petabytes of raw disk storage, eventually outputting over 300 terabytes of compressed data that's used to power every single search.
As part of that post, I got to interview Sameer and Arnab to learn more about the history of the webmap and why they moved from our proprietary infrastructure to using Hadoop.
One of the points I try to make during the interview is that this a huge milestone for Hadoop. Yahoo! is using Hadoop in a very large scale (and growing) production deployment. It's not just an experiment or research project. There's real money on the line. (It's too bad we had a technical glitch in the video right as we were discussing a Really Big Number.)
As Eric says in that post:
The Webmap launch demonstrates the power of Hadoop to solve truly Internet-sized problems and to function reliably in a large scale production setting. We can now say that the results generated by the billions of Web search queries run at Yahoo! every month depend to a large degree on data produced by Hadoop clusters.
It looks to me like 2008 and 2009 are going to be big growth years for the Hadoop project--and not just at Yahoo!
Stay tuned...
Update: You can get a Quicktime version of this video now.
February 16, 2008
Republicans Kiss Google's Ass...
I threw up a little bit in my mouth this morning while reading the press release titled 2008 Republican National Convention Names Official Innovation Provider.
Embracing technology that will propel the 2008 Republican National Convention to the forefront of the digital age, the GOP today announced that Google Inc. will serve as the Republican National Convention's Official Innovation Provider. Convention President and Chief Executive Officer Maria Cino made the announcement in a unique video posted to the convention's new YouTube channel (www.youtube.com/gopconvention2008). The video is also showcased on the convention's website (www.GOPConvention2008.com), and highlights Google's cutting-edge, computer-generated SketchUp graphics of the Xcel Energy Center, where the convention will be held.
I didn't know that the Republican campaign was so hard up for innovation that they needed to get it from Corporate America, but okay...
As Official Innovation Provider, Google Inc. will enhance the GOP's online presence with new applications, search tools, and interactive video. In addition, Google will help generate buzz and excitement in advance of the convention through its proven online marketing techniques.
On-line marketing (AdWords and AdSense, presumably) generating excitement. Yeah. Sure. I get excited by ads all the time, don't you? Especially Republican ads!
The convention's official website, www.GOPConvention2008.com, will eventually feature a full-range of Google products, including Google Apps, Google Maps, SketchUp, and customized search tools, which will make navigating the site easier. The convention's YouTube channel will enable visitors to upload, view, and share online videos. These innovative technologies will also help the GOP streamline convention organization and expand its online reach across websites, mobile devices, blogs, and email.
So they've figured out how to embed stuff in their web site to make it easier and, presumably, make up for their inability to get together a web team that could design a site that's easy to navigate? Yeah, I'd brag about that too.
I was tempted to re-write the release without all the buzzwords and over-the-top language, but I have to hit the road soon for a long drive. I guess it pretty much speaks for itself.
I'm not sure who's paying who here, but the republicans sure are kissing some Google Ass. It kinda makes you wonder what the revenue share on this deal is, doesn't it?
Either way, a dumb thing like this is an excellent way to lose credibility in my mind. I'm surprised they didn't also announce HTML as their official markup language and HTTP as the site's preferred protocol.
[Apparently I'm not the only one. See also, GOP Names Google Its Official Innovation Provider from the Wall Street Journal.]
February 15, 2008
Why Hardware Sucks and Backups and Clouds Matter
It was only about 7 months ago that I wrote Google Docs vs. the Hassle of Microsoft Office and Friends in which I said:
Last week I lost a ton of productivity because the hard disk on my laptop failed. There's a long story behind this.
The short version is that I knew it was failing for a few weeks and, yes, I had backups. The IT folks got me a new notebook (an HP nc6400 which isn't bad, really) and I've spent quite a bit of time getting my stuff running again.
Would you believe that I'm on the verge of repeating this already?
Here's the support ticket I just filed with our IT group at work:
Subject: My nc6440 notebook seems to have a failing hard disk or controller
In the last week, my laptop has become flakey. I've been seeing an increasing number of these errors in my event log:
http://jeremy.zawodny.com/pics/laptop-disk-errors.png
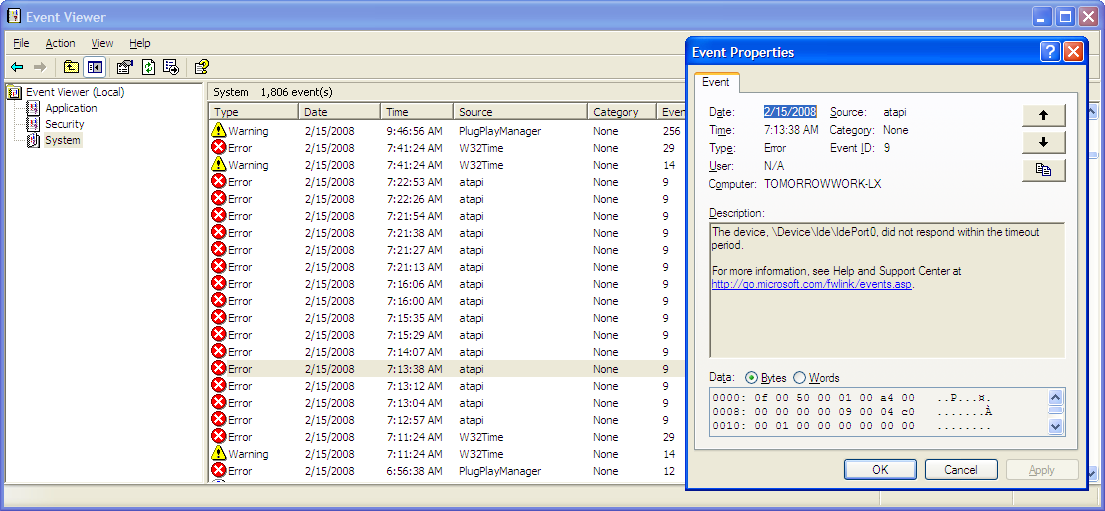{kind=link}
And yesterday I could swear I heard it making the dreaded "clicking" noise that's often a sign of imminent death. This machine has been quite stable since the day I got it, but it managed to bluescreen for the first time yesterday and it has locked up hard on me twice so far today.
Would it be possible to replace the disk, cloning the existing one in the process? Bonus points if the new one is bigger. :-)
*sigh*
Amusingly, one of the poster children for cloud computing is Amazon.com. And their S3 service had a major outage today.
So there's that.
Anyway, this is a good reminder to write about my backup strategy soon. I'll likely be putting to good use... again.
February 14, 2008
Virtualization and Personal Web Hosting
I made an off-hand remark to a friend of mine the other day about the future of my personal web hosting. Partly inspired by Sun's recent acquisition of Innotek (makers of VirtualBox) and partly by thinking I've been doing on and off since Xen and Amazon's EC2 took off.
 I essentially said that when my existing web servers--those physically hosted up in a data center in San Francisco--finally give up, I'll probably replace them with a few VM images running on a yet-to-be-discovered virtual machine hosting provider.
I essentially said that when my existing web servers--those physically hosted up in a data center in San Francisco--finally give up, I'll probably replace them with a few VM images running on a yet-to-be-discovered virtual machine hosting provider.
For the last few years, my personal web servers have been far more than I need. They have more than sufficient CPU and memory (even though they're 4+ years old). Disk space for is about the only place I forsee much growth. So it seems to just make sense to get hosted on a service that'll let me build and upload a Debian virtual machine to host my web presence and give it a static IP address.
The funny thing is that Amazon's service would be prefect for this, except that they don't offer a static IP option--at least not one that I can find. So I may end up on someone like JohnCompanies in the future.
It's been fascinating to see all the work in virtualization over the last few years. VMWare was clearly a pioneer here, but the technology is practically comoditized at this point.
What's next?
February 13, 2008
Layoffs and Social Media
Boy, it's been quite a week so far.
 I had not anticipated how quickly news of the layoffs (specific people leaving or being asked to leave) would spread on-line. But with blogs, Twitter, TechMeme, Facebook, LinkedIn, IM, Valleywag (sigh), and TechCrunch it's remarkably easy to find out who is affected.
I had not anticipated how quickly news of the layoffs (specific people leaving or being asked to leave) would spread on-line. But with blogs, Twitter, TechMeme, Facebook, LinkedIn, IM, Valleywag (sigh), and TechCrunch it's remarkably easy to find out who is affected.
I have to say, it's rather spooky. It gives a whole new meaning to the phrase "public company."
Had I thought about it in advance, I would have seen this coming. But watching the situation evolve in real-time has been a little disconcerting. And having it all happen against the backdrop of a $150 million acquisition and a corporate takeover bid makes it all the more surreal.
To any former Yahoo folks looking for work: feel free to ping me (LinkedIn, email) if you'd like a hand. I've already heard from a few companies looking for good ex-Yahoos. And I may encourage some to post on my job board too. From what I've been seeing and hearing, there's a lot of good work out there, so take your time and enjoy a bit of a break before jumping right back into the fray.
February 12, 2008
Yosemite Mirror Lake Hike in Winter
Last weekend we ventured into Yosemite National Park to hike the Mirror Lake Loop Trail (see hikes). We weren't looking for anything terribly difficult, but walking through all that snow (without snow shoes) definitely made it more challenging than last time.

Despite appearances, the weather was pretty good. It was in the low to mid 50s, so we never even got a chill until the Sun approached the horizon a bit after 4:00pm.
More pictures are here: Mirror Lake Hike, Winter 2008
February 08, 2008
Research Publications in the Age of the Web
In Mythbusting the Google generation report, Jon Udell digs into a claim about "the Google Generation" and tries to find out where the evidence comes from. What he finds is that it's not as easy as it should be. The deeper you go, the more you have to dig because the papers are all published in PDF and contain no hyperlinks.
Eventually he concludes:
But do you see the irony here? The study making this claim was constructed and published in a way that resists all efforts to evaluate its relevance, accuracy, or authority. Which hardly matters, since none of the reporting about the study seems to have made any such effort.
Pioneering research shows Google Generation is a myth? So far as I can see, that report says more about the researchers who wrote it, and about the reporters who reacted to it, than it says about any real or imaginary trends.
Ouch.
The larger issue (one of them) has been bugging me for a while now. The Web is clearly not going away. So why is it that so many respected journals and research publishing outlets completely fall down when it comes to providing actual URLs that point to supporting material?
This stuff shouldn't be rocket surgery.
You need to assume that people will discover and read your material on-line, in a web browser. Make it EASY for them to verify your claims and understand where the reasoning comes from. It'll actually make your case stronger in the long run.
February 05, 2008
Using YSlow to Grade the Presidential Candidate Web Sites
Nicole Sullivan and the Exceptional Performance Team at Yahoo used the popular YSlow Firefox/Firebug extension to grade the site performance of the 2008 presidential candidates.
How did they do? Overall, atrociously, all the candidates failed the YSlow exam except Mike Gravel who earned a "D". Page weight was a problem for Barack Obama, whose site weighed in at almost 700Kb. It was even worse for Mitt Romney, whose site weighed a whopping 1,531Kb. I hope he doesn't have supporters trying to make contributions on dialup modems!
Democrats got better grades in almost all performance subjects tested, in particular response times and page weight. They improved user experience for returning visitors by setting an Expires headers and improving the full cache user experience. This helped propel them to a performance GPA of "C" despite their failing YSlow grade. Republicans never managed to overcome the deficit and finished the semester with an "F".
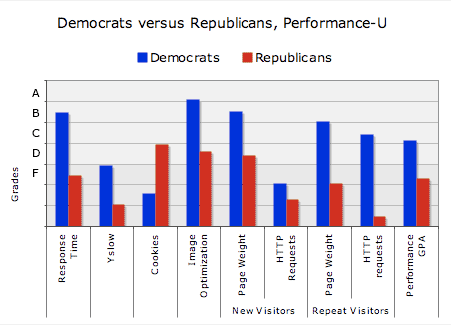
I doubt that site performance will be a factor in the voting, but it'd be quite amusing if there turned out to be a relationship between the performance numbers and votes cast for each of them.
See Also:
- YSlow Screencast and Lessons Learned
- YSlow Released on YDN
- YSlow for Firebug
- Exceptional Performance on YDN
February 04, 2008
My Ross Perot Days
I like to look back and laugh at myself. It's fun to see how some things have changed over the years while others have not.
Over the weekend, I was making room in my filing cabinet for some paperwork and came across a few folders that collected my college era stuff: transcripts, official documents, and so on. Among them was a clipping from The BG News (our campus newspaper). It's a letter to the editor that I wrote during the presidential campaign for the 1992 election: Perot will not win, but he should. I was working to organize the Ross Perot for President Campaign on the BGSU campus back then.
It is below. Click the image to read a slightly larger version.

Man, that takes me back... and gives me a good chuckle at the same time. :-)
February 02, 2008
More on the Yahoo buyout offer from Microsoft
It's been about a day since I first started reading and talking about Microsoft's $44 billion buyout offer for Yahoo (my current employer). And I have to say, it's been quite fascinating so far.
In all the reading I've done and discussions I've had, numerous scenarios have emerged. I don't claim (beyond a gut feel) to know how likely any of them are, but I figured I'd list them here for the sake of discussion. Bear in mind that, while I work at Yahoo, I have no inside info on this and am only posting my thoughts and ideas that I've heard from friends and others on-line. Jerry is probably too busy to answer my email anyway. :-)
Oh, and if you're one of the reporters who has called or emailed, you'll understand that I really can't go on record or talk to you about what's going on at work.
Anyway, here's the list...
- Microsoft actually does buy Yahoo for $31/share (or something in that ballpark). This is the default case in the minds of many people.
- Another large company (or group of companies, possibly including private equity funds) makes a counter offer. This will ultimately only serve to drive the price up. Microsoft will outbid.
- The Yahoo Board of Directors decides to outsource Yahoo's search advertising (and possibly search) business to rival Google. This entails a long-term partnership for a number of years and is sufficient to send Microsoft back to Redmond to continue working on its own search and search advertising business. I imagine this would be a very tough call to make.
- As a variation of #3, Yahoo may look to strengthen its display advertising (graphical ads) business and take some significant share of the DoubeClick acquisition as part of the deal. That makes Google the dominant contextual text advertising company and Yahoo the dominant display/banner and behavioral advertising company.
- The board simply rejects the offer and decides to continue as is. This seems quite unlikely to me. Shareholders will insist that something big happen.
No matter what happens, it's clear that this will likely be going on for quite some time. Corporate events of this magnitude take quite a bit of time to execute. I suspect that the Yahoo board of directors is considering several options that may or may not be included in the list above. Time will tell.
As an amusing side note, yesterday was one of the few days that page views to my blog home page were dramatically higher than to any of my individual posts. Apparently a lot of folks came over here to see if I had anything to say about the news. I didn't quite expect that.
February 01, 2008
Microsoft wants to buy Yahoo
That's one way to make the news, huh?

This should be interesting. I predict that today will be one of our least productive days since 9/11 at work. Just guessing.
Discuss...
See Also: