December 24, 2009
Sphinx and Gearman: A Distributed Computing AH-HA! Moment
A week ago I decided to finally get serious about putting gearman to use for search indexing. I had been batting the idea around in my head for a long time (too long, really) but figured I should just write the code and see what happens. It took less than a day to get a prototype working in our development environment, but the end result made me very happy.
Today, in our production deployment, when a sphinx cluster pulls new content to index, the master does all the work. It fetches the new and changed postings, massages them into the XML format that sphinx expects (and makes a lot of small changes along the way), invokes the indexer, and makes the new indexes available for the slaves. The second step is usually the most CPU intensive. Processing the raw data into XML involves a lot of other tweaks and changes that are very specific to Criagslist.
What I did was turn that into a gearman client/worker pair. The client (or master) simply submits processing tasks and then waits for each of them to complete. The workers fetch the data from the master, transform it, and make the transformed data available. When each task completes, the master grabs the transformed data an informs the worker that it can delete the file.
So instead of being stuck at using only the 4 CPU cores on a single box, I can run 4 workers on each of 3 machines and get 12 CPU cores involved. The end result is that I have a solid foundation for a system that can easily scale to many machines. AH-HA! Linear scaling rocks! So does relatively seamless distributed computing.
As time allows I'll have to work on deploying this in production.
October 30, 2009
Recent Sphinx Updates
 If you use the Sphinx search engine and have been watching the development branch (0.9.10) and wondering when to upgrade, I'm here to tell you that "now" is a great time. As of r2037, the last major issue I regularly saw has been fixed. The other big bug was fixed in r2031.
If you use the Sphinx search engine and have been watching the development branch (0.9.10) and wondering when to upgrade, I'm here to tell you that "now" is a great time. As of r2037, the last major issue I regularly saw has been fixed. The other big bug was fixed in r2031.
Late last week I began testing those fixes in a "burn-in" test I've developed that makes liberal use of indextool --check. Instead of seeing index corruption within an hour, I saw none. After 3 days of no failures, I deployed it to a subset of our search back-end servers. Yesterday we deployed it to half of the remaining servers.
So far, so good!
I should note that all our index corruption was merge related. Sphinx wasn't building corrupt indexes out of the box, but the merges (usually filtering merges) could produce corrupted indexes.
We were upgrading from a lightly patched version of r1894. That meant rebuilding our indexes to use the new and more compact format. Some of the obvious benefits of the upgrade:
- smaller disk and memory footprint
- pre-fork support to spawn searchd children at start up
- more reliable shutdown and pid file handling
- kill lists
- mysql protocol support
- lots of small optimizations and fixes
Thanks to the Sphinx team for their excellent work. I look forward to the release of Sphinx 1.0.
April 06, 2009
Sponsor Our Ride For Diabetes (Tour de Cure 2009)
 In early May, Kathleen and I will be participating it the Tour de Cure 2009, a bike ride to raise awareness and money for Diabetes. Craigslist (my employer) is sponsoring a team that we'll both be riding on. Collectively, our team is trying to raise $75,000 during this years ride.
In early May, Kathleen and I will be participating it the Tour de Cure 2009, a bike ride to raise awareness and money for Diabetes. Craigslist (my employer) is sponsoring a team that we'll both be riding on. Collectively, our team is trying to raise $75,000 during this years ride.
If you have a few bucks to spare for a good cause, please consider sponsoring me or sponsoring my wife (or both!). It's for a very good cause.
We're both riding the 25 mile course and would love even a $1/mile contribution. As a bonus, Craigslist is matching all our donations. So if you donate $25, your contribution becomes $50 thanks to the company's generosity.
Here are links for a bit more information:
You can visit either of our pages to pledge on-line. And if you're interested in riding, visit our team page.
Thanks for any support you can offer!
March 05, 2009
New Craigslist Search Features
I haven't said a lot here about what I've been working on at Craigslist recently. But Craig mentioned me today in his blog and that made me remember that I should say something. :-)
Much of my work has been behind the scenes infrastructure stuff, but some of that is translating into new features that craigslist users can see. And, as of this morning, a lot more users are seeing the fruits of that labor.
As I noted a few weeks back in Sphinx Search at Craigslist, I've been hacking a lot on search. Here's a screen shot to show you what I've been calling "nearby search" (though "nearby results" is probably more appropriate).
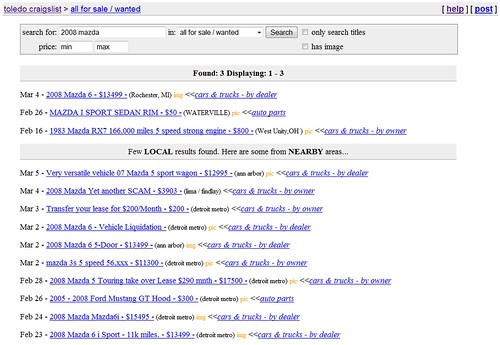
If you run a search in a city and there aren't many results, we'll also run the search in nearby areas to see if we can find matches there too. The above example was a search for "2008 mazda" in my hometown of Toledo, Ohio. The "nearby" results are clearly separated from local matches and local matches are still given priority.
The feedback has been generally positive so far. Though, with any change, some folks aren't happy. I can't say it's going to stay in this exact form. We may need to tweak the interface, the radius of the nearby search areas, and so on. But on the whole I think it's a helpful improvement when you're looking for something that's a bit harder to find and you're willing to drive an hour or two.
As of earlier today, it's available in most smaller and medium sized US cities. It'll probably come to the remainder of cities before long too. I've been testing it for about a week and a half, starting with about a dozen cities and then adding about twenty more late last week. This morning I mostly flipped the big switch.
Of course, this opened the flood gates for similar feature requests: custom radius searches, state wide searching, search ALL of craigslist, etc.
In related news, a couple months back I expanded the search help page to include advanced search syntax, including grouping, negation, OR queries, and more.
January 16, 2009
Sphinx Search at Craigslist
A couple days ago, Andrew posted a news item titled Sphinx goes billions to the Sphinx web site.
Last but not least, Powered By section, now at 113 sites and counting, was updated and restyled. I had long wondered how much Sphinx search queries are performed per month if we sum all the sites using it, and whether we already hit 1B page views per month or not. Being open-source, there's no easy way to tell. But now with the addition of craigslist to Powered By list I finally know that we do. Many thanks to Jeremy Zawodny who worked hard on making that happen, my itch is no more. :-)
Well, I guess the cat's out of the bag! My first project at Craigslist was replacing MySQL FULLTEXT indexing with Sphinx. It wasn't the easiest road in the world, for a variety of reasons, but we got it all working and it's been humming along very well ever since. And I learned a heck of a lot about both Sphinx and craigslist internals in the process too.
I'm not going to go into a lot of details on the implementation here, other than to say Sphinx is faster and far more resource efficient than MySQL was for this task. In the MySQL and Search and Craigslist talk I'm giving at the 2009 MySQL Users Conference, I'll go into a lot more detail about the unique problems we had and how we solved them.
For what it's worth, the implementation isn't really done. I did update the search help page on the site to reflect some of the capabilities (hey, look! OR searches!) but there are features I have planned that I'd like to expose as time allows.
January 11, 2009
A Job That Matters
In Tim O'Reilly's Work on Stuff that Matters he elaborated on three criteria that constitute "stuff that matters" for his readers:
- Work on something that matters to you more than money.
- Create more value than you capture.
- Take the long view.
A number of folks where surprised when I announced that I was joining craigslist back in July but it's an organization that I really admire. Having been there about 6 months now, I can definitely say that it's a job that matters based on Tim's thinking and my own.
Every time I meet someone and tell them where I work, their reaction is quite positive. They've had a good experience with craigslist, like the service, love the philosophy, and so on. Craigslist matters ordinary people--not just technology nuts.
Similarly, I know that we create more value than we capture. The majority of our service is free and usage seems to be growing all the time. People I talk to get such good responses with craigslist classifieds (compared to, say, newspapers) that I know we're giving people more than their money's worth.
As for taking the long view, I think being a non-public company helps that a lot. I've rarely thought about what "the next quarter" will bring. It's quite a contrast from my years at Yahoo. When we're discussing technology infrastructure, I'm always trying to think ahead a year or two (or more). But the day to day ups and downs just don't feel as important the way we operate. I like that.
All in all, I've been very happy with the change and am glad that Tim posted something that helped me to explain what I like about it.
August 02, 2008
Two weeks into my new job at craigslist...
Many people have asked (via IM, email, Twitter) how my new job is going, what craigslist is like, etc. So here are a few thoughts about my first two weeks in the new job.
The Commute
Despite what folks said in the comments of my little announcement, the commute really isn't that bad. Taking I-280 from Willow Glen (San Jose) up to near Golden Gate Park is about 55 minutes from pulling out of the garage to parking in San Francisco. And I've been able to find parking on Lincoln each time I've gone up--usually within 4-6 blocks from the office.
So 55 minutes of driving plus about 10 minutes of walking (which is good for me anyway) is very manageable if you're not doing it every day. If I did, I'd be less up-beat about it, I'm sure.
Having said that, I am going to experiment with the mass transit options as well. I'd like to give all the reasonable options a fair shake.
The Hardware
My laptop, a Lenovo ThinkPad T61 running Ubuntu Linux is performing quite well. It's had one lockup that I cannot attribute to anything in particular. But other than that, it's a joy to work on--especially with Emacs Snapshot and it's most excellent font rendering. (Learning VIM is still on my todo list...)
The biggest hassle so far has been VPN related. Every once in a while my laptop decides to reconnect to my wireless router at home and when it does it replaces the custom resolv.conf file with my "normal" home one. That results in a VPN that sort of works and sort of doesn't. I'm getting better at noticing when this happens and fixing it, but I really need to find a way to keep that from happening at all.
The Culture
In two weeks, I've only had one experience that I would come close to classifying as a "meeting." There really aren't conference rooms (yay!) but it did involve a whiteboard. However, unlike meetings I'm used to, it involved only the most essential people, had a clearly defined goal, and was very useful to me.
The engineering team has a great old-school Perl and Unix mentality (and sense of humor) to it that I really dig. Our private IRC channel is filled with a mix of useful information sharing and old fashioned joking, complaining, and ranting. It reminds me a lot of Yahoo in the 1999-2000 time frame.
The Food
Unlike Yahoo, craigslist has an abundance of nearby eating establishments within very short walking distance. I suspect that it'll take months of time before I've sampled what's nearby.
The Work
What am I actually doing?
Well, it's a mix of things at this stage. Since I know only a little bit about how things actually work, I'm asking a lot of questions and trying to get a sense of what's what and where. That always takes time in a new environment and with a new code base. But eventually the day does come when you suddenly realize that it's not an issue anymore and you must have things mostly figured out.
I'm also playing with alternatives to our current search. I've spent a week or so getting to know Sphinx, the open source search engine by Andrew Aksyonoff. People often use it as a replacement for MySQL's full-text search capabilities.
So far I'm quite impressed with it's speed and capabilities, not to mention Andrew's willingness to offer advice and suggestions. I've also been using Jon Schutz's Sphinx::Search Perl module. I've had to slightly modify the code of both to get them to perform the way we'd like, but that modifications aren't terribly extensive. As is often the case, what took the most time was figuring out what I really wanted to do and then how to do it.
I may have more to say about all this later.
Hiring
It looks like we've got a bit more room at craigslist. As Jim mentioned on the craigslist blog:
Worth mentioning that the CL tech hiring bit remains set to "1" for star LAMPerl developers, systems heavyweights, and networking wizards.
If you're a great Perl hacker, amazingly skilled networking geek, or someone who really knows systems and data center stuff, we may be waiting for you.
Ping me if you're interested and we'll get the ball rolling.
Finally...
Anyway, that's the story so far.
Am I happy in my new role? You bet.
Do I miss some of my old colleagues at Yahoo? Of course. In fact, I missed Chad's going away party due to a sick cat, which is a whole separate and sad story I need to tell.
See Also: Settling in to a New Environment at Craigslist
July 22, 2008
Settling in to a New Environment at Craigslist
 Yesterday was my first day as an employee at craiglist. Several folks on Twitter asked how it was, so here are my thoughts.
Yesterday was my first day as an employee at craiglist. Several folks on Twitter asked how it was, so here are my thoughts.
First off, it was a bit like a first day anywhere. I had several new people to meet, a bunch of paperwork to fill out for benefits and payroll stuff, and started to get an overview of how things work.
Unlike jobs in larger organizations, I had the pleasure of un-boxing and setting up my chair, desktop, and laptop computers. There's no "IT group" to do this stuff and that's perfectly fine with me. That's just one of the ways the size difference between a company of less than 30 people becomes apparent when you're used to well over 10,000. Specialization just can't take hold in a smaller group like that.
Aside from a new job and new people and new computer(s), I'm also in a newish office that's referred to as "the annex." It's just down the street from the main craigslist office but isn't nearly as full yet.
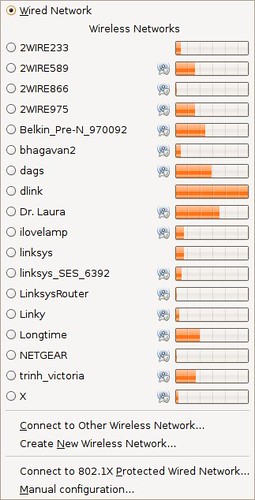
Unlike Yahoo, there are many, many places to eat within a very short walk from the office. To get a sense of how dense an area I'm in, check out all the wifi networks visible from my desk. At Yahoo, we were in a corporate campus environment, so all you saw were Yahoo networks.
At the end of yesterday, I'd setup the bare minimum stuff on my new laptop (a 15.4" ThinkPad T61 running Ubuntu), desktop (also running Ubuntu), many accounts and passwords, email access, an IRC client for our internal channel, got wiki access, and a few other bits.
I'm looking forward to learning what makes things tick and how I can make the better. I'm already getting a sense for the challenges we face in running such a popular service with a small team.
Honestly, it's a refreshing change from the larger environments that I've worked in before. Plus, the commute wasn't as bad as I expected yesterday. Thanks to all the tips and advice I got last time, I headed up with the right expectations. That makes a difference.